1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
| INFO[2024-12-11T15:08:23+08:00] Creating a new enclave for Starlark to run inside...
INFO[2024-12-11T15:08:25+08:00] Enclave 'local-eth-testnet' created successfully
Container images used in this run:
> ethpandaops/lighthouse:stable - remotely downloaded
> ethpandaops/ethereum-genesis-generator:3.4.2 - remotely downloaded
> ethereum/client-go:latest - remotely downloaded
> python:3.11-alpine - remotely downloaded
> protolambda/eth2-val-tools:latest - remotely downloaded
> badouralix/curl-jq - remotely downloaded
......
Starlark code successfully run. Output was:
{
"all_participants": [
{
"cl_context": {
"beacon_grpc_url": "",
"beacon_http_url": "http://172.16.4.11:4000",
"beacon_service_name": "cl-1-lighthouse-geth",
"cl_nodes_metrics_info": [
{
"config": {
"labels": null,
"scrape_interval": "15s"
},
"name": "cl-1-lighthouse-geth",
"path": "/metrics",
"url": "172.16.4.11:5054"
}
],
"client_name": "lighthouse",
"enr": "enr:-Mm4QGoJFz_8BxhUo1_qcU99AlMtQg08SE_lrbH0B3cVOdoiFyHNA12IrI2DwAsZG7AvSeocDB9TcFad33Om5sd9Gc0Dh2F0dG5ldHOIAAAAAMAAAACDY3NjBIRldGgykE-3JeFgAAA4AOH1BQAAAACCaWSCdjSCaXCErBAEC4RxdWljgiMpiXNlY3AyNTZrMaEDwNCUN06NbFU4oqKnXHkTMdcdNTlr_xwC33QSFfCdcL6Ic3luY25ldHMAg3RjcIIjKIN1ZHCCIyg",
"http_port": 4000,
"ip_addr": "172.16.4.11",
"multiaddr": "/ip4/172.16.4.11/tcp/9000/p2p/16Uiu2HAmRdf6aDAhx764sqQkD9BYQxFmyAXoCaGETKCwb49MTLgm",
"peer_id": "16Uiu2HAmRdf6aDAhx764sqQkD9BYQxFmyAXoCaGETKCwb49MTLgm",
"snooper_enabled": false,
"snooper_engine_context": null,
"supernode": false,
"validator_keystore_files_artifact_uuid": "1-lighthouse-geth-0-63"
},
"cl_type": "lighthouse",
"el_context": {
"client_name": "geth",
"el_metrics_info": [
{
"config": {
"labels": null,
"scrape_interval": "15s"
},
"name": "el-1-geth-lighthouse",
"path": "/debug/metrics/prometheus",
"url": "172.16.4.10:9001"
}
],
"engine_rpc_port_num": 8551,
"enode": "enode://e273007e4a0cc96fb52d02e132643dcdc7dabee68bdf65e7a538f01e33682ae137c0f25ca51301f99e9ac2ba2ca625af9caa6c692246597872f9d0bac4d6c3ab@172.16.4.10:30303",
"enr": "enr:-Ki4QEtrZL_kOZOzlrm5bzYHqXuAExc82OpFTVlzlWpvfkbAThI2xjDaR44kByHuwzs0Lg4QpasiuBLWFzvq0Tuk7cuGAZO0jpf1g2V0aMzLhKMFvEuFCVgqux6CaWSCdjSCaXCErBAEColzZWNwMjU2azGhA-JzAH5KDMlvtS0C4TJkPc3H2r7mi99l56U48B4zaCrhhHNuYXDAg3RjcIJ2X4N1ZHCCdl8",
"ip_addr": "172.16.4.10",
"rpc_http_url": "http://172.16.4.10:8545",
"rpc_port_num": 8545,
"service_name": "el-1-geth-lighthouse",
"ws_port_num": 8546,
"ws_url": "ws://172.16.4.10:8546"
},
"el_type": "geth",
"ethereum_metrics_exporter_context": null,
"remote_signer_context": null,
"remote_signer_type": "web3signer",
"snooper_beacon_context": null,
"snooper_engine_context": null,
"vc_context": {
"client_name": "lighthouse",
"metrics_info": {
"config": {
"labels": null,
"scrape_interval": "15s"
},
"name": "vc-1-geth-lighthouse",
"path": "/metrics",
"url": "172.16.4.12:8080"
},
"service_name": "vc-1-geth-lighthouse"
},
"vc_type": "lighthouse",
"xatu_sentry_context": null
}
],
"final_genesis_timestamp": "1733901086",
"genesis_validators_root": "0xd61ea484febacfae5298d52a2b581f3e305a51f3112a9241b968dccf019f7b11",
"network_id": "3151908",
"network_params": {
"additional_preloaded_contracts": {},
"altair_fork_epoch": 0,
"bellatrix_fork_epoch": 0,
"capella_fork_epoch": 0,
"churn_limit_quotient": 65536,
"custody_requirement": 4,
"data_column_sidecar_subnet_count": 128,
"deneb_fork_epoch": 0,
"deposit_contract_address": "0x4242424242424242424242424242424242424242",
"devnet_repo": "ethpandaops",
"eip7594_fork_epoch": 100000002,
"eip7594_fork_version": "0x60000038",
"ejection_balance": 16000000000,
"electra_fork_epoch": 100000000,
"eth1_follow_distance": 2048,
"fulu_fork_epoch": 100000001,
"genesis_delay": 20,
"genesis_gaslimit": 30000000,
"max_blobs_per_block": 6,
"max_per_epoch_activation_churn_limit": 8,
"min_validator_withdrawability_delay": 256,
"network": "kurtosis",
"network_id": "3151908",
"network_sync_base_url": "https://snapshots.ethpandaops.io/",
"num_validator_keys_per_node": 64,
"prefunded_accounts": {},
"preregistered_validator_count": 0,
"preregistered_validator_keys_mnemonic": "giant issue aisle success illegal bike spike question tent bar rely arctic volcano long crawl hungry vocal artwork sniff fantasy very lucky have athlete",
"preset": "mainnet",
"samples_per_slot": 8,
"seconds_per_slot": 12,
"shard_committee_period": 256
},
"pre_funded_accounts": [
{
"address": "0x8943545177806ED17B9F23F0a21ee5948eCaa776",
"private_key": "bcdf20249abf0ed6d944c0288fad489e33f66b3960d9e6229c1cd214ed3bbe31"
},
{
"address": "0xE25583099BA105D9ec0A67f5Ae86D90e50036425",
"private_key": "39725efee3fb28614de3bacaffe4cc4bd8c436257e2c8bb887c4b5c4be45e76d"
},
{
"address": "0x614561D2d143621E126e87831AEF287678B442b8",
"private_key": "53321db7c1e331d93a11a41d16f004d7ff63972ec8ec7c25db329728ceeb1710"
},
{
"address": "0xf93Ee4Cf8c6c40b329b0c0626F28333c132CF241",
"private_key": "ab63b23eb7941c1251757e24b3d2350d2bc05c3c388d06f8fe6feafefb1e8c70"
},
{
"address": "0x802dCbE1B1A97554B4F50DB5119E37E8e7336417",
"private_key": "5d2344259f42259f82d2c140aa66102ba89b57b4883ee441a8b312622bd42491"
},
{
"address": "0xAe95d8DA9244C37CaC0a3e16BA966a8e852Bb6D6",
"private_key": "27515f805127bebad2fb9b183508bdacb8c763da16f54e0678b16e8f28ef3fff"
},
{
"address": "0x2c57d1CFC6d5f8E4182a56b4cf75421472eBAEa4",
"private_key": "7ff1a4c1d57e5e784d327c4c7651e952350bc271f156afb3d00d20f5ef924856"
},
{
"address": "0x741bFE4802cE1C4b5b00F9Df2F5f179A1C89171A",
"private_key": "3a91003acaf4c21b3953d94fa4a6db694fa69e5242b2e37be05dd82761058899"
},
{
"address": "0xc3913d4D8bAb4914328651C2EAE817C8b78E1f4c",
"private_key": "bb1d0f125b4fb2bb173c318cdead45468474ca71474e2247776b2b4c0fa2d3f5"
},
{
"address": "0x65D08a056c17Ae13370565B04cF77D2AfA1cB9FA",
"private_key": "850643a0224065ecce3882673c21f56bcf6eef86274cc21cadff15930b59fc8c"
},
{
"address": "0x3e95dFbBaF6B348396E6674C7871546dCC568e56",
"private_key": "94eb3102993b41ec55c241060f47daa0f6372e2e3ad7e91612ae36c364042e44"
},
{
"address": "0x5918b2e647464d4743601a865753e64C8059Dc4F",
"private_key": "daf15504c22a352648a71ef2926334fe040ac1d5005019e09f6c979808024dc7"
},
{
"address": "0x589A698b7b7dA0Bec545177D3963A2741105C7C9",
"private_key": "eaba42282ad33c8ef2524f07277c03a776d98ae19f581990ce75becb7cfa1c23"
},
{
"address": "0x4d1CB4eB7969f8806E2CaAc0cbbB71f88C8ec413",
"private_key": "3fd98b5187bf6526734efaa644ffbb4e3670d66f5d0268ce0323ec09124bff61"
},
{
"address": "0xF5504cE2BcC52614F121aff9b93b2001d92715CA",
"private_key": "5288e2f440c7f0cb61a9be8afdeb4295f786383f96f5e35eb0c94ef103996b64"
},
{
"address": "0xF61E98E7D47aB884C244E39E031978E33162ff4b",
"private_key": "f296c7802555da2a5a662be70e078cbd38b44f96f8615ae529da41122ce8db05"
},
{
"address": "0xf1424826861ffbbD25405F5145B5E50d0F1bFc90",
"private_key": "bf3beef3bd999ba9f2451e06936f0423cd62b815c9233dd3bc90f7e02a1e8673"
},
{
"address": "0xfDCe42116f541fc8f7b0776e2B30832bD5621C85",
"private_key": "6ecadc396415970e91293726c3f5775225440ea0844ae5616135fd10d66b5954"
},
{
"address": "0xD9211042f35968820A3407ac3d80C725f8F75c14",
"private_key": "a492823c3e193d6c595f37a18e3c06650cf4c74558cc818b16130b293716106f"
},
{
"address": "0xD8F3183DEF51A987222D845be228e0Bbb932C222",
"private_key": "c5114526e042343c6d1899cad05e1c00ba588314de9b96929914ee0df18d46b2"
},
{
"address": "0xafF0CA253b97e54440965855cec0A8a2E2399896",
"private_key": "4b9f63ecf84210c5366c66d68fa1f5da1fa4f634fad6dfc86178e4d79ff9e59"
}
]
}
⭐ us on GitHub - https://github.com/kurtosis-tech/kurtosis
INFO[2024-12-11T15:11:10+08:00] ==========================================================
INFO[2024-12-11T15:11:10+08:00] || Created enclave: local-eth-testnet ||
INFO[2024-12-11T15:11:10+08:00] ==========================================================
Name: local-eth-testnet
UUID: b134e2cd4ffa
Status: RUNNING
Creation Time: Wed, 11 Dec 2024 15:08:23 CST
Flags:
========================================= Files Artifacts =========================================
UUID Name
eeac0b67fe11 1-lighthouse-geth-0-63
0ca90fbaddae el_cl_genesis_data
02724177f009 final-genesis-timestamp
6579d6313c44 genesis-el-cl-env-file
6236b016ccf1 genesis_validators_root
d65d356d27a3 jwt_file
77d5e8aa3bf1 keymanager_file
f873ac882893 prysm-password
7f0f603a0154 validator-ranges
========================================== User Services ==========================================
UUID Name Ports Status
38a34f4ff219 cl-1-lighthouse-geth http: 4000/tcp -> http://127.0.0.1:54095 RUNNING
metrics: 5054/tcp -> http://127.0.0.1:54096
tcp-discovery: 9000/tcp -> 127.0.0.1:54097
udp-discovery: 9000/udp -> 127.0.0.1:60155
714c863fd14f el-1-geth-lighthouse engine-rpc: 8551/tcp -> 127.0.0.1:54056 RUNNING
metrics: 9001/tcp -> http://127.0.0.1:54057
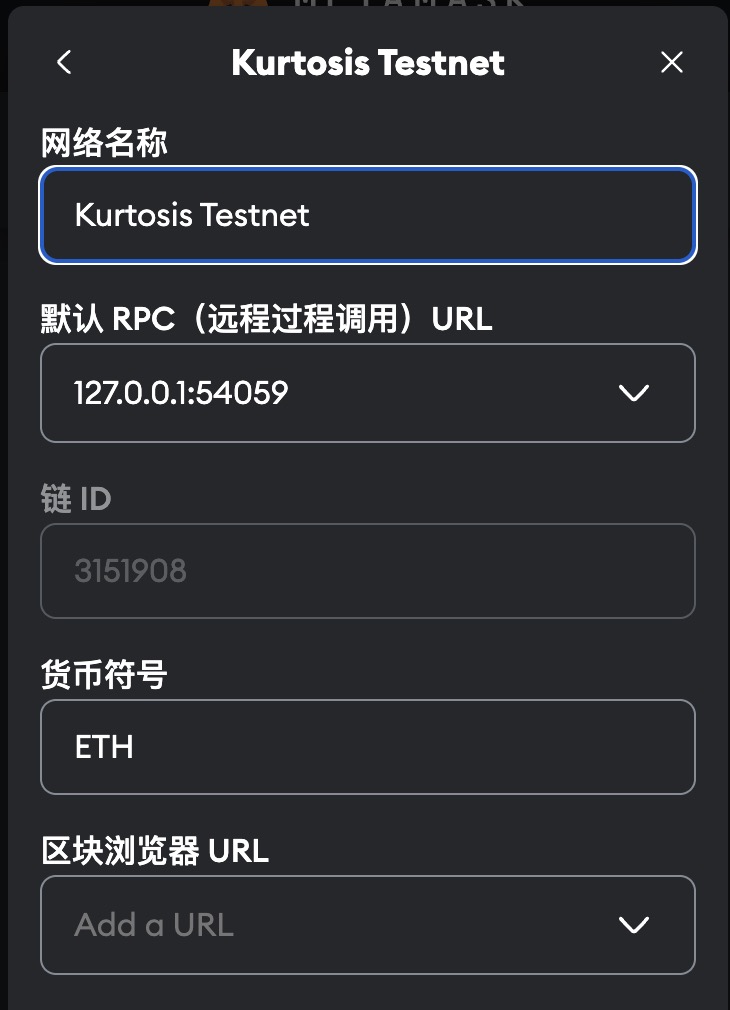
rpc: 8545/tcp -> 127.0.0.1:54059
tcp-discovery: 30303/tcp -> 127.0.0.1:54058
udp-discovery: 30303/udp -> 127.0.0.1:54093
ws: 8546/tcp -> 127.0.0.1:54055
ef18a854d243 validator-key-generation-cl-validator-keystore <none> RUNNING
0f4da064ec7f vc-1-geth-lighthouse metrics: 8080/tcp -> http://127.0.0.1:54168 RUNNING
|