介绍
docker不是一项新技术,docker是老旧技术的组合,为了更方便使用容器技术,docker提供了简单方便的UI。docker隔离资源主要用到了两种技术namespace、cgroup。
Namespace
namespace是linux内核提供的隔离技术,它包括六种资源隔离,UTS(主机名与域名)、IPC(信号量、消息队列和共享内存)、PID(进程编号)、NET(网络设备、网络栈、端口…)、Mount(文件系统、挂载点)、User(用户和用户组)。
| Type | Sys Params | ker ver |
|---|---|---|
| UTS | CLONE_NEWUTS | 2.6.19 |
| IPC | CLONE_NEWIPC | 2.6.19 |
| PID | CLONE_NEWPID | 2.6.24 |
| NET | CLONE_NEWNET | 2.6.29 |
| Mount | CLONE_NEWNS | 2.4.19 |
| User | CLONE_NEWUSER | 3.8 |
操作系统调用接口:
- clone()
创建一个独立的进程独立的namespace - setns()
使用已有的一个namespace - unshare()
不启动新进程,在原进程上进行namespace隔离
docker run中提供了使用namespace的接口:
1 | docker run --help | grep -i namespace |
UTS
提供了主机名和域名的隔离,这样每个容器就可以拥有了独立的主机名和域名,在网络上可以被视作一个独立的节点而非宿主机上的一个进程。
docker在run或create时,使用-h或--hostname指定hostname
IPC
IPC是Unix/linux下进程间通讯的一种方式,包括信号量、消息队列、共享内存。容器内部进程间通信对宿主机来说,实际上是具有相同PID namespace中的进程间通信,因此需要一个唯一的标识符来进行区别。申请IPC资源就申请了这样一个全局唯一的32位ID,所以IPC namespace中实际上包含了系统IPC标识符以及实现POSIX消息队列的文件系统。在同一个IPC namespace下的进程彼此可见,而与其他的IPC namespace下的进程则互相不可见。
在宿主机上创建IPC(以消息队列为例):
1 | ipcmk -Q |
在宿主机上查询IPC:
1 | ipcs |
在容器中查询IPC:
1 | docker exec -it net_5 ipcs |
PID
它对进程PID重新标号,即两个不同namespace下的进程可以有同一个PID。每个PID namespace都有自己的计数程序。内核为所有的PID namespace维护了一个树状结构,最顶层的是系统初始时创建的,我们称之为root namespace。他创建的新PID namespace就称之为child namespace(树的子节点),而原先的PID namespace就是新创建的PID namespace的parent namespace(树的父节点)。通过这种方式,不同的PID namespaces会形成一个等级体系。所属的父节点可以看到子节点中的进程,并可以通过信号等方式对子节点中的进程产生影响。反过来,子节点不能看到父节点PID namespace中的任何内容。
* 每个PID namespace中的第一个进程“PID 1“,都会像传统Linux中的init进程一样拥有特权,起特殊作用。
* 一个namespace中的进程,不可能通过kill或ptrace影响父节点或者兄弟节点中的进程,因为其他节点的PID在这个namespace中没有任何意义。
* 如果你在新的PID namespace中重新挂载/proc文件系统,会发现其下只显示同属一个PID namespace中的其他进程。(挂载/proc 文件系统尤为重要)
* 在root namespace中可以看到所有的进程,并且递归包含所有子节点中的进程。
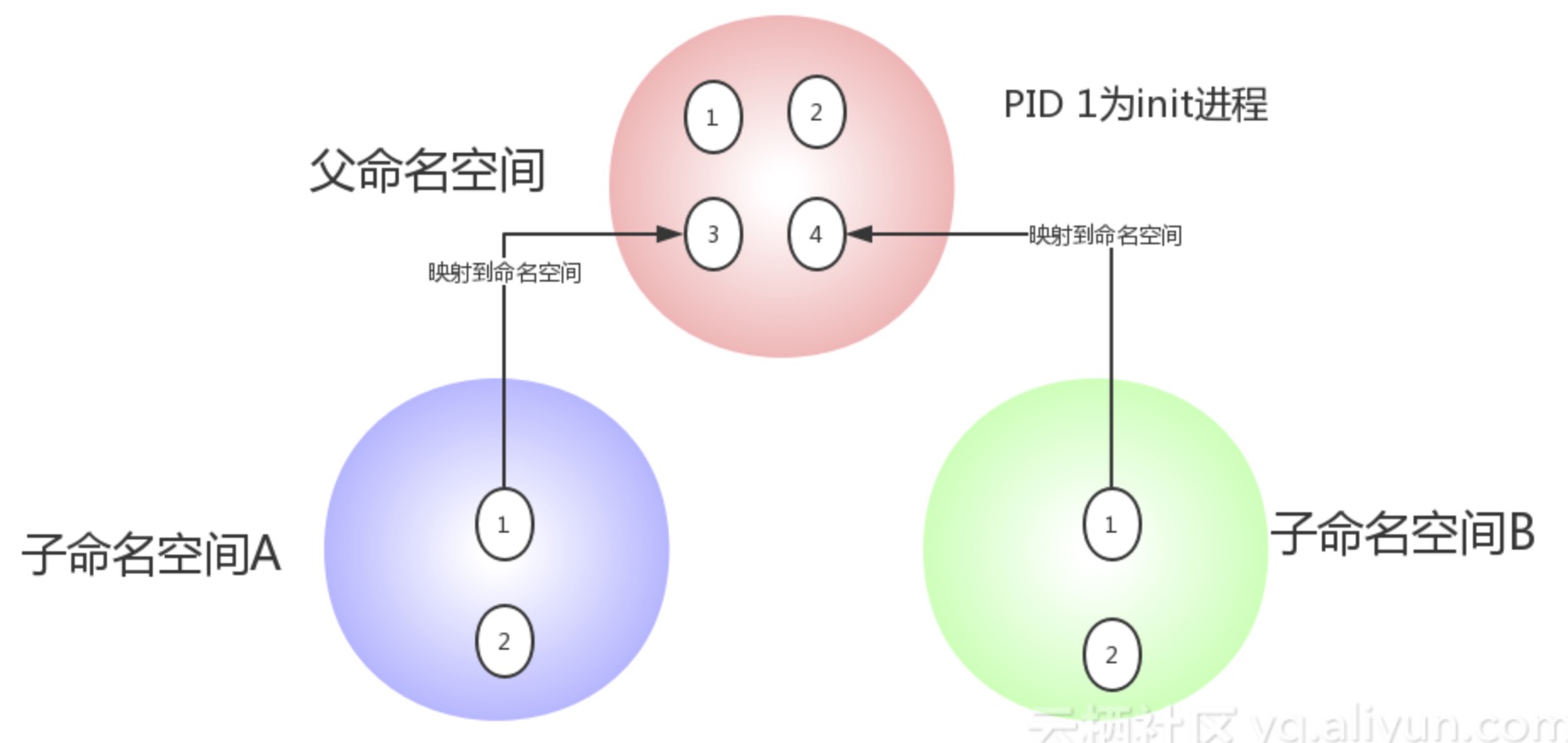
以容器的ceph-mon节点为例:
1 | 宿主机上查看 ceph-mon 进程 |
NET
Pv4和IPv6协议栈、IP路由表、防火墙、/proc/net目录、/sys/class/net目录、端口(socket)等等。一个物理的网络设备最多存在在一个network namespace中,你可以通过创建veth pair(虚拟网络设备对:有两端,类似管道,如果数据从一端传入另一端也能接收到,反之亦然)在不同的network namespace间创建通道,以此达到通信的目的。
一般情况下,物理网络设备都分配在最初的root namespace(表示系统默认的namespace,在PID namespace中已经提及)中。但是如果你有多块物理网卡,也可以把其中一块或多块分配给新创建的network namespace。需要注意的是,当新创建的network namespace被释放时(所有内部的进程都终止并且namespace文件没有被挂载或打开),在这个namespace中的物理网卡会返回到root namespace而非创建该进程的父进程所在的network namespace。
当我们说到network namespace时,其实我们指的未必是真正的网络隔离,而是把网络独立出来,给外部用户一种透明的感觉,仿佛跟另外一个网络实体在进行通信。为了达到这个目的,容器的经典做法就是创建一个veth pair,一端放置在新的namespace中,通常命名为eth0,一端放在原先的namespace中连接物理网络设备,再通过网桥把别的设备连接进来或者进行路由转发,以此网络实现通信的目的。
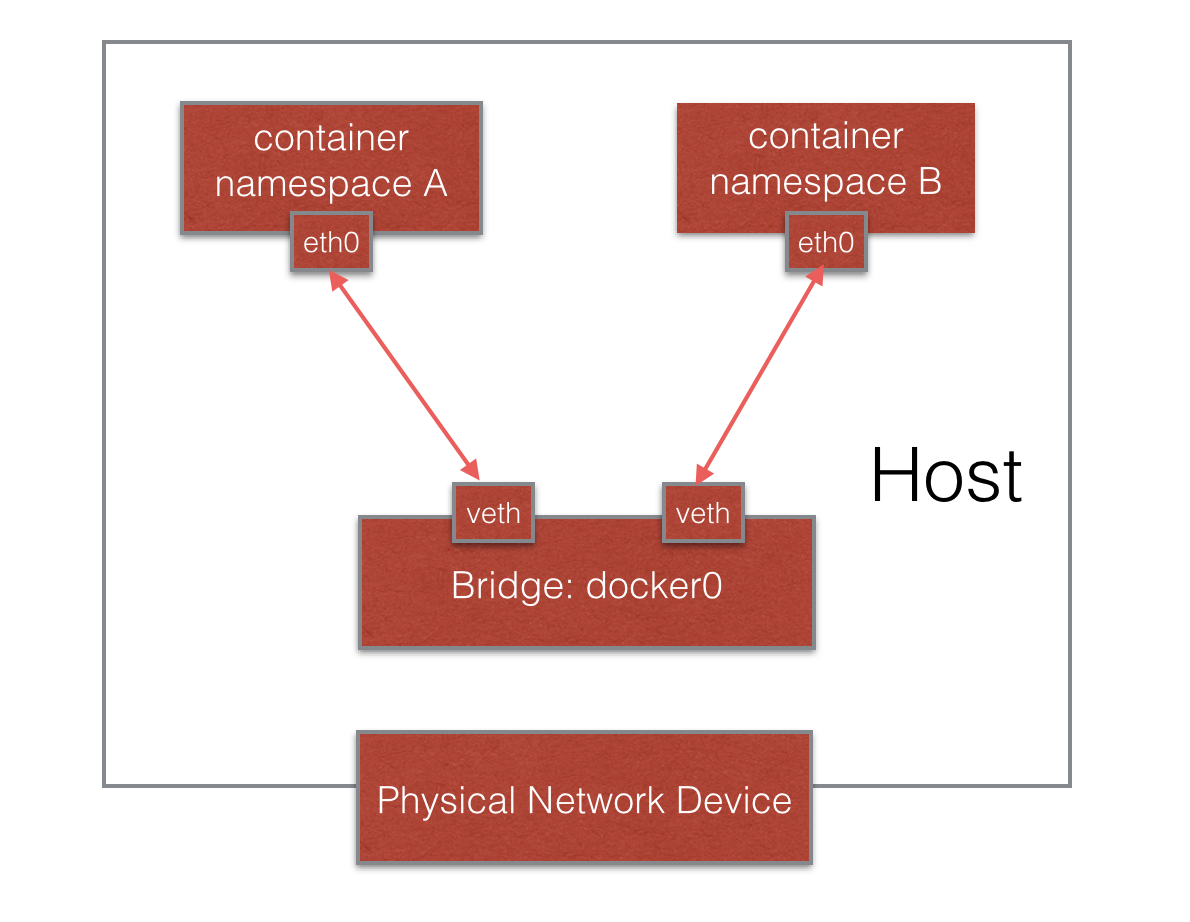
可通过ip netns、brctl管理Network Namespace,docker创建的netns路径为/proc/{进程ID}/ns/net,ip netns访问的默认路径为/var/run/netns/。
若需要访问其Network Namespace内部,先创建软连接链至ip netns访问路径,然后使用ip netns exec访问该网络内部。
1 | 在ip netns访问路径下创建network namespace的软链接 |
Mount
隔离后,不同mount namespace中的文件结构发生变化也互不影响。你可以通过/proc/[pid]/mounts查看到所有挂载在当前namespace中的文件系统,还可以通过/proc/[pid]/mountstats看到mount namespace中文件设备的统计信息,包括挂载文件的名字、文件系统类型、挂载位置等等。(此处用到了mount propagation 技术)
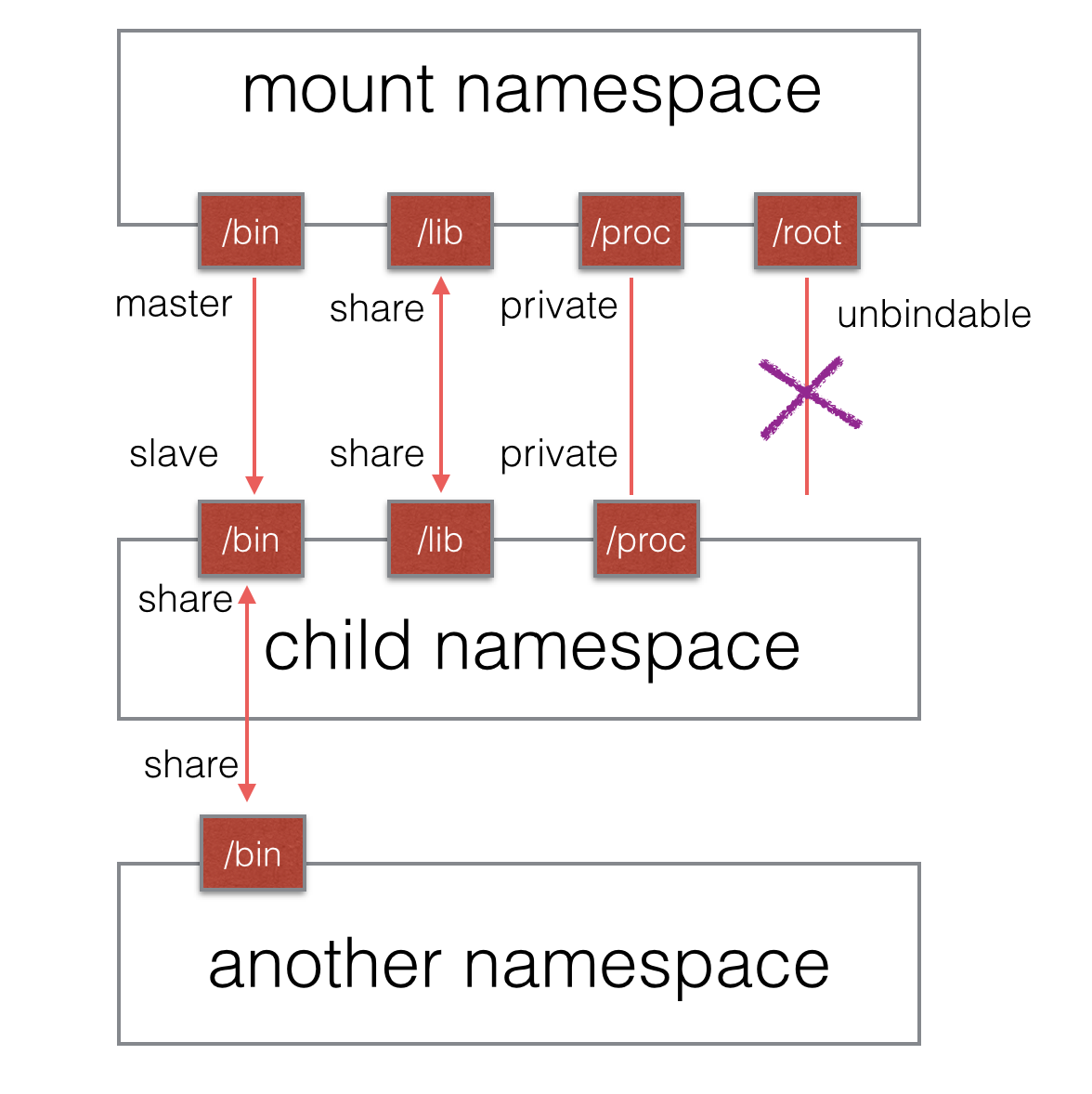
上图mount挂载方式有待确认。
USER
主要隔离了安全相关的标识符(identifiers)和属性(attributes),包括用户ID、用户组ID、root目录、key(指密钥)以及特殊权限。说得通俗一点,一个普通用户的进程通过clone()创建的新进程在新user namespace中可以拥有不同的用户和用户组。这意味着一个进程在容器外属于一个没有特权的普通用户,但是他创建的容器进程却属于拥有所有权限的超级用户,这个技术为容器提供了极大的自由。
docker通过/proc/{进程ID}/uid_map和/proc/{进程ID}/gid_map把容器中的uid、gid和真实系统的uid、gid给映射在一起,格式为:ID-inside-ns ID-outside-ns length。
- ID-inside-ns 表示在容器内显示的uid或gid
- ID-outside-ns 表示在容器外映射的真实的uid或gid
- length 表示映射范围,一般为1,表示一一对应(把ID-outside-ns ~(ID-outside-ns+length) 映射到 ID-inside-ns ~(ID-inside-ns+length)上)
cgroups
Control Groups(cgroups),是Linux 内核提供的一种可以限制、记录、隔离进程组所使用的物理资源(如 cpu、memory、磁盘IO等等) 的机制,被LXC、docker等很多项目用于实现进程资源控制。
cgroups子系统:
- cpu
使用调度程序提供对 CPU 的 cgroup 任务访问 - cpuset
为cgroup中的任务分配独立CPU(在多核系统)和内存节点 - devices
可允许或者拒绝 cgroup 中的任务访问设备 - blkio
为块设备设定输入/输出限制,比如物理设备(磁盘,固态硬盘,USB 等等) - freezer
挂起或者恢复 cgroup 中的任务 - memory
设定 cgroup 中任务使用的内存限制,并自动生成由那些任务使用的内存资源报告 - net_cls
使用等级识别符(classid)标记网络数据包,可允许 Linux 流量控制程序(tc)识别从具体 cgroup 中生成的数据包
CPU
cpu-shares
在docker create/run容器时可以通过--cpu-shares参数来指定容器所使用的CPU加权值。默认情况下,每个docker容器的cpu-shares值都是1024。单独一个容器的cpu-shares是没有意义的,只在多个容器分配的资源紧缺时,也就是说在需要对容器使用的资源进行限制时,才会生效。配之后,可通过./cgroup/cpu/docker/<容器ID>/cpu.shares查看。
cpu-period & cpu-quota
- cpu-period 用来指定容器对CPU的使用要在多长时间内做一次重新分配
- cpu-quota 用来指定在这个周期内,最多可以有多少时间用来跑这个容器
在docker create/run时使用,参数为--cpu-period和--cpu-quota单位为微秒,cpu-period的默认值为0.1秒(100000 微秒),cpu-quota的默认值为-1(表示不控制)。配置后,可通过./cgroup/cpu/docker/<容器ID>/cpu.cfs_period_us和./cgroup/cpu/docker/<容器ID>/cpu.cfs_quota_us查看。
cpuset
docker可使用--cpuset-cpus和--cpuset-mems参数控制容器运行限定使用哪些cpu和内存节点。配之后,可通过./cgroup/cpuset/docker/<容器ID>/cpuset.cpus和./cgroup/cpuset/docker/<容器ID>/cpuset.mems查看。
*** 注:对于具有NUMA的服务器很重要 ***
Memory
在docker create/run时,可以对内存资源加以限制。
- kernel-memory
使用参数--kernel-memory,限制内核内存,该内存不会被交换到swap上。 - memory
使用参数--memory,设置容器使用的最大内存上限。默认单位为byte,可以使用K、G、M等带单位的字符串。 - memory-reservation
使用参数--memory-reservation,启用弹性的内存共享,当宿主机资源充足时,允许容器尽量多地使用内存,当检测到内存竞争或者低内存时,强制将容器的内存降低到memory-reservation所指定的内存大小。不设置此选项时,有可能出现某些容器长时间占用大量内存,导致性能上的损失。 - memory-swap
使用参数--memory-swap,设置总内存大小,相当于内存和swap大小的总和,设置-1时,表示swap分区大小是无限的。默认单位为byte,可以使用K、G、M等带单位的字符串。 - memory-swappiness
使用参数--memory-swappiness,设置控制进程将物理内存交换到swap分区的倾向,系数越小,就越倾向于使用物理内存。值范围为0-100。当值为100时,表示尽量使用swap分区;当值为0时,表示禁用容器 swap 功能(这点不同于宿主机,宿主机 swappiness 设置为 0 也不保证 swap 不会被使用)
Block Device
I/O
- device-read-bps
限制此设备上的读速度(bytes per second),单位可以是kb、mb或者gb - device-read-iops
通过每秒读IO次数来限制指定设备的读速度 - device-write-bps
限制此设备上的写速度(bytes per second),单位可以是kb、mb或者gb - device-write-iops
通过每秒写IO次数来限制指定设备的写速度 - blkio-weight
容器默认磁盘IO的加权值,有效值范围为10-100。要使-–blkio-weight生效,需要保证IO的调度算法为CFQ
echo "cfq" > /sys/block/<设备名>/queue/scheduler - blkio-weight-device
针对特定设备的IO加权控制。其格式为DEVICE_NAME:WEIGHT
Volume
使用参数--storage-opt,传入dm.basesize=<容量大小>可以设置rootfs大小。如果不设置dm.basesize,默认值为10G,若要使dm.basesize生效,storage driver 必须是 device mapper。
设置rootfs大小后,需要重启docker服务,并且--storage-opts参数需要在启动docker服务时使用。
以RHEL7.2为例,需要修改/etc/systemd/system/multi-user.target.wants/docker.service中/usr/bin/dockerd的参数。