背景
拜占庭位于如今的土耳其的伊斯坦布尔,是东罗马帝国的首都。由于当时拜占庭罗马帝国国土辽阔,为了防御目的,因此每个军队都分隔很远,将军与将军之间只能靠信差传消息。 在战争的时候,拜占庭军队内所有将军和副官必需达成一致的共识,决定是否有赢的机会才去攻打敌人的阵营。但是,在军队内有可能存有叛徒和敌军的间谍,左右将军们的决定又扰乱整体军队的秩序。在进行共识时,结果并不代表大多数人的意见。这时候,在已知有成员谋反的情况下,其余忠诚的将军在不受叛徒的影响下如何达成一致的协议,拜占庭问题就此形成。
拜占庭将军问题是一个协议问题,拜占庭帝国军队的将军们必须全体一致的决定是否攻击某一支敌军。问题是这些将军在地理上是分隔开来的,并且将军中存在叛徒。叛徒可以任意行动以达到以下目标:欺骗某些将军采取进攻行动;促成一个不是所有将军都同意的决定,如当将军们不希望进攻时促成进攻行动;或者迷惑某些将军,使他们无法做出决定。如果叛徒达到了这些目的之一,则任何攻击行动的结果都是注定要失败的,只有完全达成一致的努力才能获得胜利。
拜占庭假设是对现实世界的模型化,由于硬件错误、网络拥塞或断开以及遭到恶意攻击,计算机和网络可能出现不可预料的行为。拜占庭容错协议必须处理这些失效,并且这些协议还要满足所要解决的问题要求的规范。这些算法通常以其弹性t作为特征,t表示算法可以应付的错误进程数。
很多经典算法问题只有在t<n/3时才有解,如拜占庭将军问题,其中n是系统中进程的总数。
为了解决拜占庭将军问题,图灵奖大神Leslie Lamport提出了Paxos算法,该算法可以帮助解决分布式系统中的一致性问题。
原理
在分布式系统中,为了保证数据的高可用,我们会将数据保留多个副本,这些副本会放置在不同的物理机上。为了对用户提供正确的读写,我们需要保证这些放置在不同物理机上的副本是一致的。
其中Proposer与Acceptor之间的交互主要有两个阶段、4类消息构成。
- Phase1
本阶段由2类消息构成prepare和promise,Proposer向网络内超过半数的Acceptor发送prepare消息 - Phase2
prepare、promise、accept、accepted。
角色
Paxos中有三类角色Proposer、Acceptor、Learner
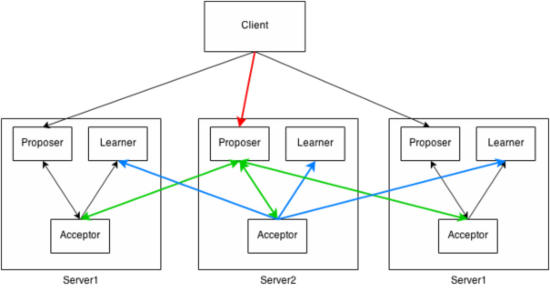
选举流程
整个Paxos算法流程分为3个阶段
- 准备阶段
- 决议阶段
- 学习阶段
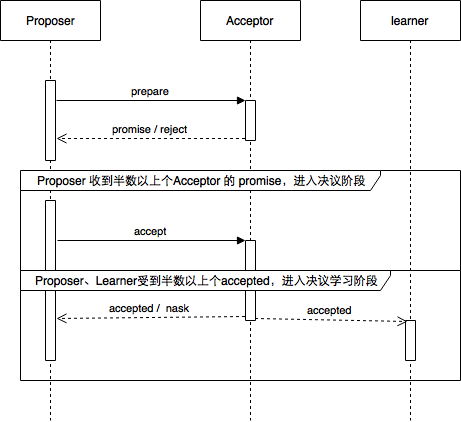
准备阶段
- Proposer向大多数Acceptor发起自己要发起Proposal(epochNo, value)的Prepare请求
- Acceptor收到Prepare请求,如果epochNo比已经接受的小的,直接拒绝; 如果epochNo比已经接受的大,保证不再接受比该epochNo小的请求,且将已经接受的epochNo最大的Proposal返回给Proposer
决议阶段
- Proposer收到大多数Acceptor的Prepare应答后,如果已经有被接受的Proposal,就从中选出epochNo最大的Proposal, 发起对该Proposal的Accept请求。如果没有已经接受的Proposal, 就自己提出一个Proposal, 发起Accept请求。
- Acceptor收到Accept请求后,如果该Proposal的epochNo比它最后一次应答的Prepare请求的epochNo要小,那么要拒绝该请求;否则接受该请求。
学习阶段
- 当各个Acceptor达到一致之后,需要将达到一致的结果通知给所有的Learner
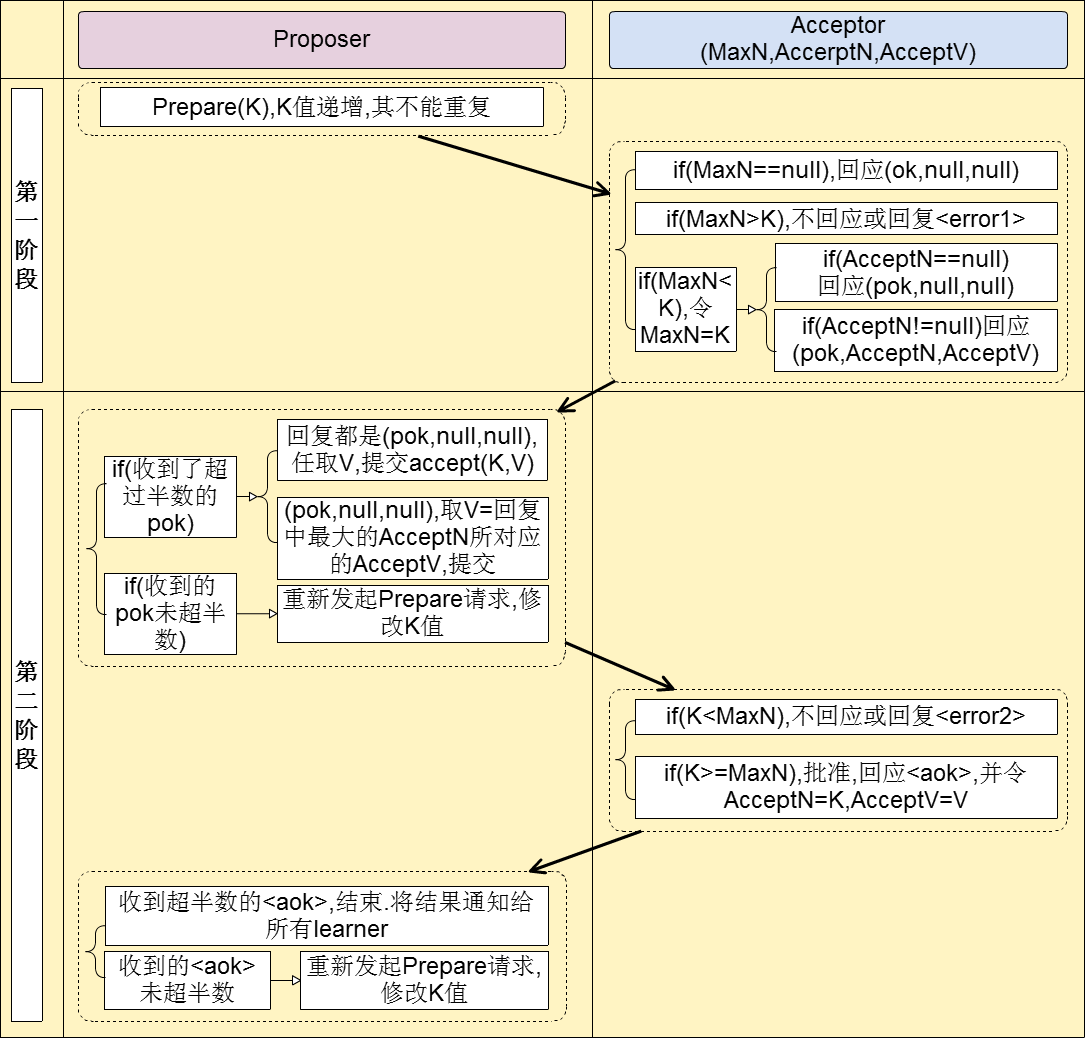
Proposer角色
(Phase1.a) 向所有的acceptors发送Prepare(i, b)请求;
(Phase2.a) 如果收到Reject(i,b)消息,那么重新发送Prepare(i,b+n),n为一个整型值,不同的proposer具有不同的n值,使得proposer之间保持一个偏序关系,保证不同的proposer不会使用相同的b值,即提案编号;
(Phase2.a) 如果收到acceptors集合的任意一个majority的Promise(i, b, V, VB)回复,那么如果所有的V均为空,proposer可以自由选取一个v(value),一般为用户提出的请求,回发Accept(i, b, v);否则回发Accept(i,b,V);
(Phase2.b) 如果收到Nack(b),回到(Phase1.a)发送Prepare(i,b+n);
(Phase2.b) 如果收到任意一个majority所有成员的Accepted(i,b,v)消息(表明投票已经完成)。这个过程learner也能收到Accepted消息,learner查看i是否为当前需要确认的iid,如果是则立即执行这个被批准的决议v;否则将该Accepted保存下来。
Phase2.b阶段完成后,各个角色上对应该实例的状态都将变为closed状态,即该实例已经选出决议,proposer不能再提出新的提案。这样保证一个实例只能选出一个决议。在实际应用过程中,为了简化实现,常常在proposers中选举出一个leader,来充当协调者。当leader选举出来后,系统中只能由leader向acceptors发出Prepare请求,也就是说这能由leader发起提案,而其它的proposers则只干一件事,即定时检测系统中的leader是否还在工作,如果在一定时间内收不到leader的心跳消息,则剩下的proposers发起新一轮leader竞选,选取新的leader。
Acceptor
acceptor会维护一个状态记录表,表的每一行维护这样四个数据<iid, B, V, VB>, iid表示实例id。B是一个整数,用来表示同意或接受过的该提案的最高编号。V表示该提案对应的决议,里面保存着客户端发送过来的数据。VB表示已经接受过的提案的编号。
(Phase 1.b) 接收Prepare(i,b)消息,i为实例id号,b为提案编号。对于同一个i,如果b>B,那么回复Promise(i, b, V, VB),并设B=b;否则,回复Reject(i,b),其中b=B。
(Phase 2.b) 接收Accept(i, b, v),如果b<B,那么回复Nack(b)信息,其中b=B(暗示该proposer提出提案后至少有一个其它的proposer广播了具有更高编号的提案);否则设置V=v,VB=b,并且回复Accepted(i,b,v)消息。
其中:Promise(i, b, V, VB)表示向proposer保证对于该实例不再接受编号不大于b的相同iid的提案;Accepted表示向learner和proposer发送该提案被通过的消息。
Learner
learner的主要任务就是监听来自acceptors的消息,用以最终确认并学习决议(value),即被批准的提案。当learner收到来自大多数(majority)acceptors的接受消息后,就可以确定该实例(instance)的value已经被最终无歧义的确认。这个时候便可以执行决议里的操作。决议序列在所有learner上顺序都是一致的,每一个提案的发起将会触发一次Paxos过程,每个这样的过程是一个Paxos的实例。而在实际应用中常使用单增的整数来标识每一个实例,即iid(instance id)。iid从1开始,而所有从1开始到当前iid的实例都必须是已经被确认过的,即这些决议都已经被执行过。比如:learner A已经确认了前10个实例,这时iid为11的决议还没有被通过,而iid为12和13的提案已经得到大多数acceptors的接受。此时就会产生一个决议序列缺口(gap),在这种情况下,A不能跳过11直接确认12和13,而是去询问acceptors是否已经通过11的决议。只有当iid为11的决议被确认后,iid为12和13的决议才能被确认学习。
活锁问题
Todo…
应用
Paxos在Ceph Monitor应用。Monitor要做的事情很明确了,就是管理、维护和发布集群的状态信息,但是为了避免单点故障或者性能热点问题,一般使用多个Monitor来做这一件事情,也就是管理层有多个成员。集群的正常运行,首先需要管理层达成一致,达成一致就需要有一个能拍板的monitor(leader),大家都听它的就行了。所以要达成一致核心问题就是在众多monitor中选出那个能拍板的monitor。Ceph解决这个问题的方法很简单,有点类似于领导人的选举,即有资格的monitor先形成一个quorum(委员会),然后委员会的成员在quorum这个范围内选出一个leader,集群状态信息的更新以及quorum成员的维护就有这个leader负责。Leader的选取规则也比较简单,每个monitor在初始化的时候都会根据它的IP地址被赋予一个rank值,当选举leader时,rank值最小的monitor胜出当选leader。当quorum成员发生变化时(增加或者减少),都会触发重新选举流程,再选出一个leader。
monitor的代码目录结构: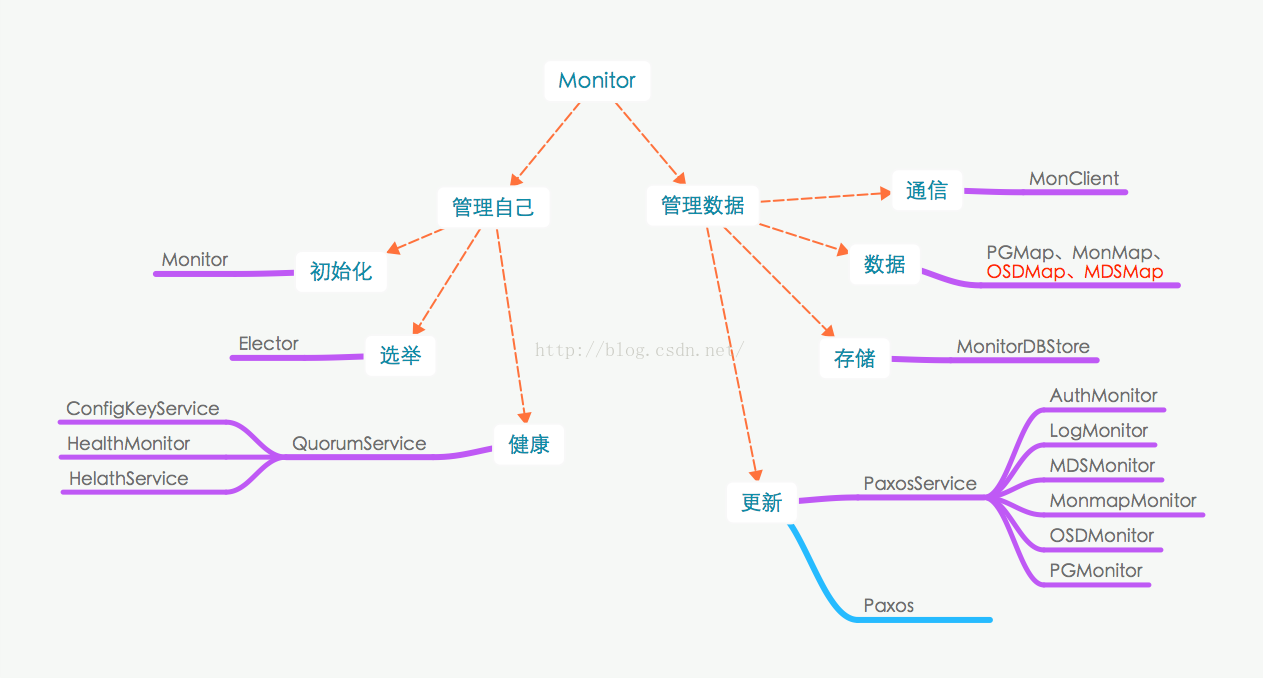
架构设计
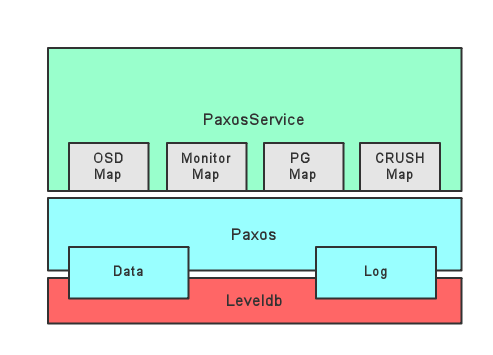
- DBStore层
数据的最终存储组件,以leveldb为例 - Paxos层
在集群上对上层提供一致的数据访问逻辑,在这一层看来所有的数据都是kv;上层的多中PaxosService将不同的组件的map数据序列化为单条value,公用同一个paxos实例 - PaxosService层
每个PaxosService代表集群的一种状态信息。对应的,Ceph Moinitor中包含分别负责OSD Map,Monitor Map, PG Map, CRUSH Map的几种PaxosService。PaxosService负责将自己对应的数据序列化为kv写入Paxos层。Ceph集群所有与Monitor的交互最终都是在调用对应的PaxosSevice功能
关键流程及结构
初始化流程
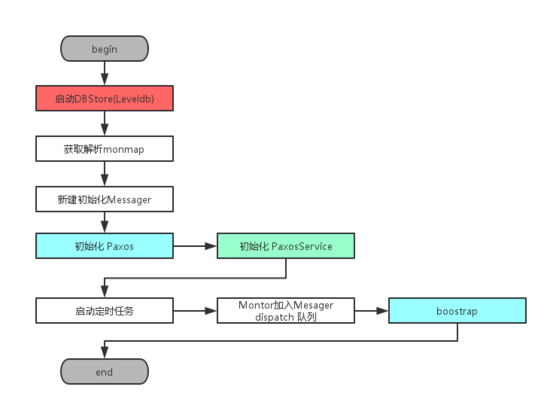
- 自下而上依次初始化上述的三大组成部分:DBStroe,Paxos,PaxoService
- 初始化Messager,并向其中注册命令执行回调函数。Messager是Ceph中的网络线程模块,Messager会在收到网络请求后,回调Moniotor在初始化阶段注册命令处理函数
- Bootstrap过程在整个Monitor的生命周期中被反复调用
Boostrap
- 执行Boostrap的Monitor节点会首先进入PROBING状态,并开始向所有monmap中其他节点发送Probing消息
- 收到Probing消息的节点执行Boostrap并回复Probing_ack,并给出自己的last_commit以及first_commit,其中first_commit指示当前机器的commit记录中最早的一条,其存在使得单个节点上可以仅保存最近的几条记录
- 收到Probing_ack的节点发现commit数据的差距早于对方first_commit,则主动发起全同步,并在之后重新Boostrap
- 收到超过半数的ack并不需要全同步时,则进入选主过程
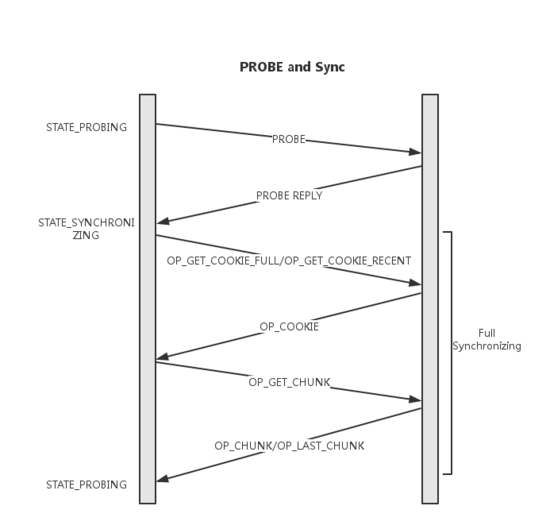
经过boostrap过程,保证可以与半数以上的节点通讯,并且节点间commit数据历史差距不大了。
select & victory
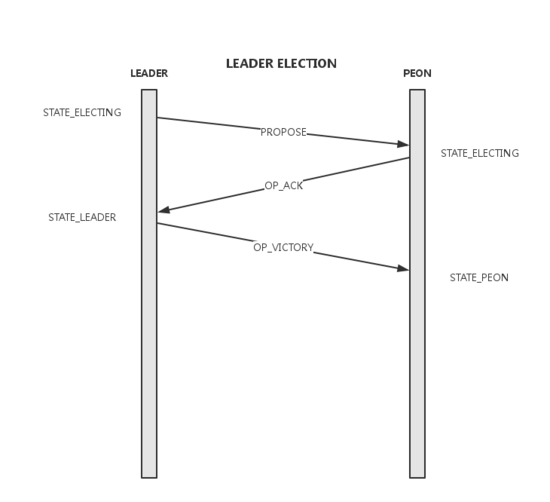
select
- 将election_epoch加1,向Monmap中的所有其他节点发送Propose消息
- 收到Propose消息的节点进入election状态并仅对有更新的election_epoch且rank值大于自己的消息答复Ack。这里的rank简单的由ip大小决定
- 发送Propose的节点统计收到的Ack数,超时时间内收到Monmap中大多数的ack后可进入victory过程,这些发送ack的节点形成quorum
victory
- election_epoch加1,可以看出election_epoch的奇偶可以表示是否在选举轮次
- 向quorum中的所有节点发送VICTORY消息,并告知自己的epoch及quorum
- 当前节点完成Election,进入Leader状态
- 收到VICTORY消息的节点完成Election,进入Peon状态
recovery
经过了Boostrap、select、victory,能确定leader和peon角色,以及quorum成员。在recovery阶段将leader和quorum节点间的数据更新到一致。整个集群进入可用状态。
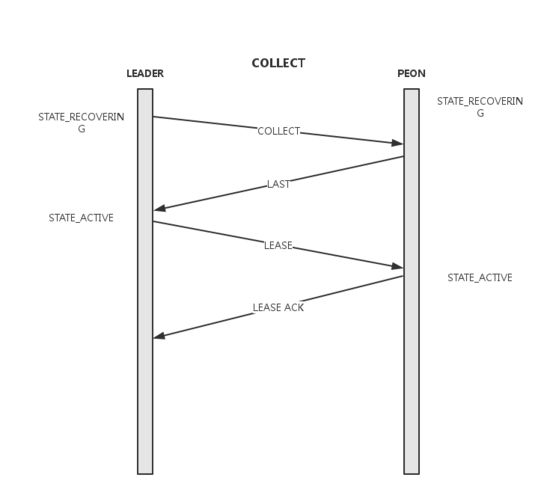
一致性读写流程
经过了上面的初始化流程,整个集群进入到一个正常状态,可以用Paxos进行一致性读写了。其中读流程比较简单,lease内的所有quorum均可以提供读服务。而所有写都会转发给leader。
一致性写流程
- leader在本地记录要提交的value,并向quroum中的所有节点发送begin消息,其中携带了要提交的value, accept_pn及last_commit
- peon收到begin消息,如果accept过更高的pn则忽略,否则将value写入db并返回accept消息。同时peon会将当前的lease过期掉,在下一次收到lease前不再提供服务
- leader收到 全部 quorum的accept后进行commit。本地commit后向所有quorum节点发送commit消息
- peon收到commit消息,本地commit数据
- leader通过lease消息将整个集群带入到active状态
状态转换
初始化阶段状态转换
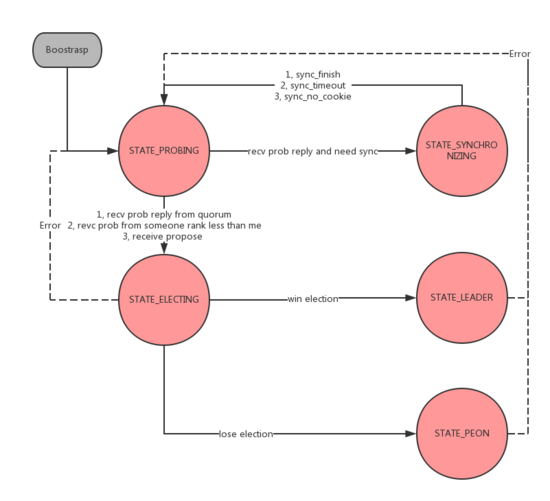
- STATE_PROBING
boostrap过程中节点间相互探测,发现数据差距 - STATE_SYNCHRONIZING
当数据差距较大无法通过后续机制补齐时,进行全同步 - STATE_ELECTING
Monitor在进行选主 - STATE_LEADER
当前Monitor成为leader - STATE_PEON
非leader节点
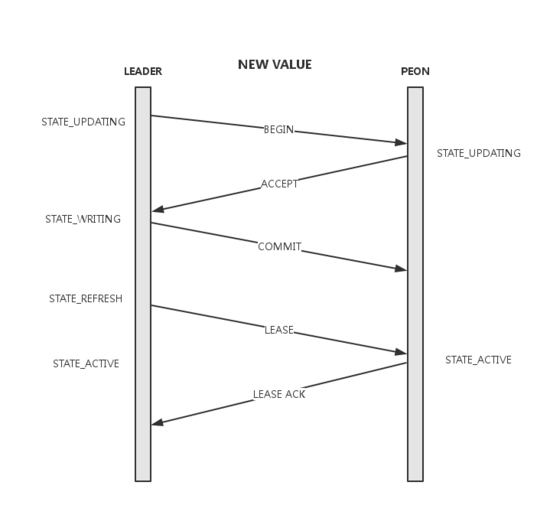
一致性读写阶段状态转换
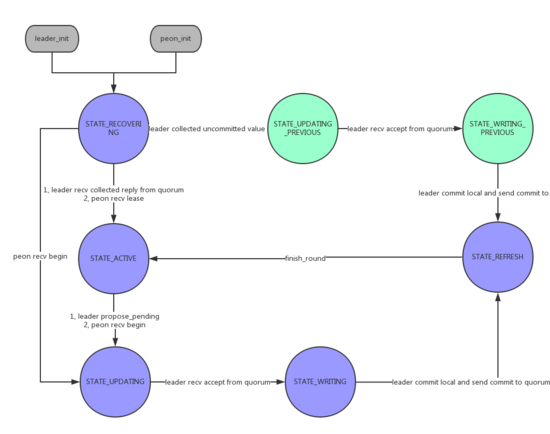
- STATE_RECOVERING
对应上述RECOVERING过程 - STATE_ACTIVE
leader可以读写或peon拥有lease - STATE_UPDATING
向quroum发送begin,等待accept - STATE_WRITING
收到accept - STATE_REFERSH
本地提交并向quorum发送commit