版本 引用代码版本:linux-3.10.104
功能
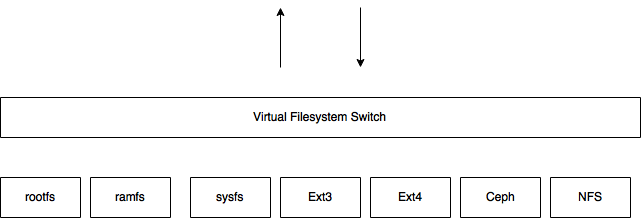
提供一个通用接口
提供各种cache以提高文件系统性能
VFS所处理的系统调用
系统调用名
说明
mount umount umount2
安装/卸载文件系统
sysfs
获取文件系统信息
ustat statfs fstatfs statfs64 fstatfs64
获取文件系统统计信息
chroot pivot_root
更改根目录
chdir fchdir getcwd
对当前目录进行操作
mkdir rmdir
创建、删除目录
getdents getdents64 readdir link unlink rename lookup_dcookie
对目录项进行操作
readlink symlink
对软连接进行操作
chown fchown lchown chown16 fchown16 lchown16
更改文件所有者
chmod fchmod utime
更改文件属性
stat fstat lstat access oldstat oldfstat oldlstat
读取文件状态
stat64 lstat64 fstat64
open close creat umask
打开、关闭、创建文件
dup dup2 fcntl fcntl64
对文件描述符进行操作
select poll
等待一组文件描述符上发生的事件
truncate ftruncate truncate64 ftruncate64
更改文件长度
lseek
更改文件指针
read write readv writev sendfile sendfile64 readahead
进行文件I/O操作
io_setup io_submit io_getevents io_cancel io_destroy
异步I/O
pread64 pwrite64
搜索并访问文件
mmap mmap2 munmap madvise mincore remap_file_pages
处理文件内存映射
fdatasync fsync sync msync
同步文件数据
flock
处理文件锁
setxattr lsetxattr fsetxattr getxattr lgetxattr
处理文件扩展属性
fgetxattr listxattr llistxattr flistxattr removexattr
lremovexattr fremovexattr
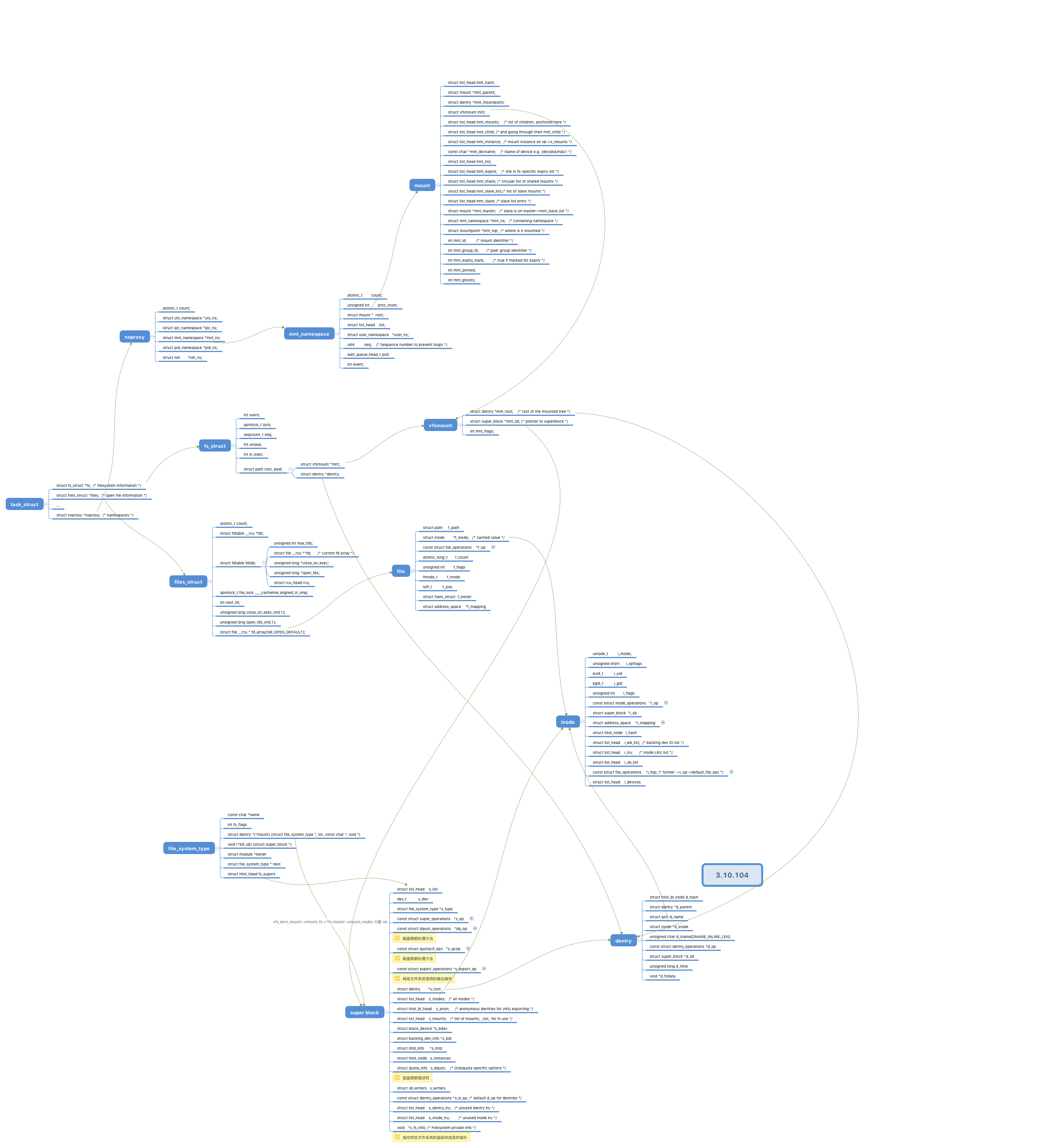
VFS数据结构
超级块对象和inode对象分别对应有物理数据,在磁盘上有静态信息。
目录项对象和文件对象描述的是一种关系,前者描述的文件与文件名的关系,后者描述的是进程与文件的关系,所以没有对应物理数据
进程每打开一个文件,就会有一个file结构与之对应。同一个进程可以多次打开同一个文件而得到多个不同的file结构,file结构描述被打开文件的属性,如文件的当前偏移量等信息
两个不同的file结构可以对应同一个dentry结构。进程多次打开同一个文件时,对应的只有一个dentry结构
在存储介质中,每个文件对应唯一的inode结点,但是每个文件又可以有多个文件名。
Inode中不存储文件的名字,它只存储节点号;而dentry则保存有名字和与其对应的节点号,所以就可以通过不同的dentry访问同一个inode
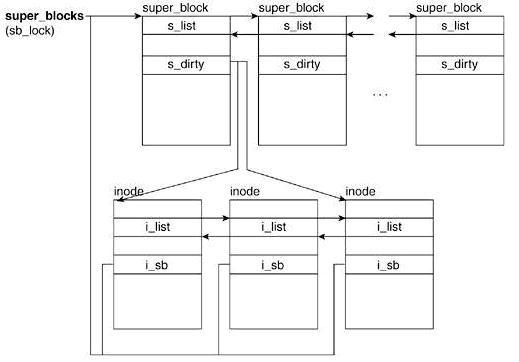
Super Block
超级块用来描述特定文件系统的信息。它存放在磁盘特定的扇区中 ,它在使用的时候将信息存在于内存中
当内核对一个文件系统进行初始化和注册时在内存为其分配一个超级块,这就是VFS超级块。即,VFS超级块是各种具体文件系统在安装时建立的,并在这些文件系统卸载时被自动删除
关键成员:
s_list
s_fs_info
alloc_super()sget()调用,在fs/super.c文件中)。在文件系统安装时,内核会调用该函数以便从磁盘读取文件系统超级块,并且将其信息填充到内存中的超级块对象中
include/linux/fs.h
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 struct super_block { struct list_head s_list ; dev_t s_dev; unsigned char s_blocksize_bits; unsigned long s_blocksize; loff_t s_maxbytes; struct file_system_type *s_type ; const struct super_operations *s_op ; const struct dquot_operations *dq_op ; const struct quotactl_ops *s_qcop ; const struct export_operations *s_export_op ; unsigned long s_flags; unsigned long s_magic; struct dentry *s_root ; struct rw_semaphore s_umount ; int s_count; atomic_t s_active; #ifdef CONFIG_SECURITY void *s_security; #endif const struct xattr_handler **s_xattr ; struct list_head s_inodes ; struct hlist_bl_head s_anon ; struct list_head s_mounts ; struct list_head s_dentry_lru ; int s_nr_dentry_unused; spinlock_t s_inode_lru_lock ____cacheline_aligned_in_smp; struct list_head s_inode_lru ; int s_nr_inodes_unused; struct block_device *s_bdev ; struct backing_dev_info *s_bdi ; struct mtd_info *s_mtd ; struct hlist_node s_instances ; struct quota_info s_dquot ; struct sb_writers s_writers ; char s_id[32 ]; u8 s_uuid[16 ]; void *s_fs_info; unsigned int s_max_links; fmode_t s_mode; u32 s_time_gran; struct mutex s_vfs_rename_mutex ; char *s_subtype; char __rcu *s_options; const struct dentry_operations *s_d_op ; int cleancache_poolid; struct shrinker s_shrink ; atomic_long_t s_remove_count; int s_readonly_remount; };
super_operation include/linux/fs.h
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 struct super_operations { struct inode *(*alloc_inode )(struct super_block *sb ); void (*destroy_inode)(struct inode *); void (*dirty_inode) (struct inode *, int flags); int (*write_inode) (struct inode *, struct writeback_control *wbc); int (*drop_inode) (struct inode *); void (*evict_inode) (struct inode *); void (*put_super) (struct super_block *); int (*sync_fs)(struct super_block *sb, int wait); int (*freeze_fs) (struct super_block *); int (*unfreeze_fs) (struct super_block *); int (*statfs) (struct dentry *, struct kstatfs *); int (*remount_fs) (struct super_block *, int *, char *); void (*umount_begin) (struct super_block *); int (*show_options)(struct seq_file *, struct dentry *); int (*show_devname)(struct seq_file *, struct dentry *); int (*show_path)(struct seq_file *, struct dentry *); int (*show_stats)(struct seq_file *, struct dentry *); #ifdef CONFIG_QUOTA ssize_t (*quota_read)(struct super_block *, int , char *, size_t , loff_t ); ssize_t (*quota_write)(struct super_block *, int , const char *, size_t , loff_t ); #endif int (*bdev_try_to_free_page)(struct super_block*, struct page*, gfp_t ); int (*nr_cached_objects)(struct super_block *); void (*free_cached_objects)(struct super_block *, int ); };
Inode
索引节点,索引节点与文件一一对应,并且随文件存在而存在。内存中索引节点由一个inode结构表示。
include/linux/fs.h
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 struct inode { umode_t i_mode; unsigned short i_opflags; kuid_t i_uid; kgid_t i_gid; unsigned int i_flags; #ifdef CONFIG_FS_POSIX_ACL struct posix_acl *i_acl ; struct posix_acl *i_default_acl ; #endif const struct inode_operations *i_op ; struct super_block *i_sb ; struct address_space *i_mapping ; #ifdef CONFIG_SECURITY void *i_security; #endif unsigned long i_ino; union { const unsigned int i_nlink; unsigned int __i_nlink; }; dev_t i_rdev; loff_t i_size; struct timespec i_atime ; struct timespec i_mtime ; struct timespec i_ctime ; spinlock_t i_lock; unsigned short i_bytes; unsigned int i_blkbits; blkcnt_t i_blocks; #ifdef __NEED_I_SIZE_ORDERED seqcount_t i_size_seqcount; #endif unsigned long i_state; struct mutex i_mutex ; unsigned long dirtied_when; struct hlist_node i_hash ; struct list_head i_wb_list ; struct list_head i_lru ; struct list_head i_sb_list ; union { struct hlist_head i_dentry ; struct rcu_head i_rcu ; }; u64 i_version; atomic_t i_count; atomic_t i_dio_count; atomic_t i_writecount; const struct file_operations *i_fop ; struct file_lock *i_flock ; struct address_space i_data ; #ifdef CONFIG_QUOTA struct dquot *i_dquot [MAXQUOTAS ]; #endif struct list_head i_devices ; union { struct pipe_inode_info *i_pipe ; struct block_device *i_bdev ; struct cdev *i_cdev ; }; __u32 i_generation; #ifdef CONFIG_FSNOTIFY __u32 i_fsnotify_mask; struct hlist_head i_fsnotify_marks ; #endif #ifdef CONFIG_IMA atomic_t i_readcount; #endif void *i_private; };
i_state 成员
I_DIRTY_SYNC
I_DIRTY_DATASYNC
I_DIRTY_PAGES
I_NEW
I_WILL_FREE
I_FREEING
I_CLEAR
I_SYNC
I_REFERENCED
I_DIO_WAKEUP
I_DIRTY
inode_operations include/linux/fs.h
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 struct inode_operations { struct dentry * (*lookup ) (struct inode *,struct dentry *, unsigned int ); void * (*follow_link) (struct dentry *, struct nameidata *); int (*permission) (struct inode *, int ); struct posix_acl * (*get_acl )(struct inode *, int ); int (*readlink) (struct dentry *, char __user *,int ); void (*put_link) (struct dentry *, struct nameidata *, void *); int (*create) (struct inode *,struct dentry *, umode_t , bool ); int (*link) (struct dentry *,struct inode *,struct dentry *); int (*unlink) (struct inode *,struct dentry *); int (*symlink) (struct inode *,struct dentry *,const char *); int (*mkdir) (struct inode *,struct dentry *,umode_t ); int (*rmdir) (struct inode *,struct dentry *); int (*mknod) (struct inode *,struct dentry *,umode_t ,dev_t ); int (*rename) (struct inode *, struct dentry *, struct inode *, struct dentry *); int (*setattr) (struct dentry *, struct iattr *); int (*getattr) (struct vfsmount *mnt, struct dentry *, struct kstat *); int (*setxattr) (struct dentry *, const char *,const void *,size_t ,int ); ssize_t (*getxattr) (struct dentry *, const char *, void *, size_t ); ssize_t (*listxattr) (struct dentry *, char *, size_t ); int (*removexattr) (struct dentry *, const char *); int (*fiemap)(struct inode *, struct fiemap_extent_info *, u64 start, u64 len); int (*update_time)(struct inode *, struct timespec *, int ); int (*atomic_open )(struct inode *, struct dentry *, struct file *, unsigned open_flag, umode_t create_mode, int *opened); } ____cacheline_aligned;
File
文件对象描述进程怎样与一个打开文件进行交互。
几个进程可以同时访问一个文件,因此文件指针必须放在文件对象而不是索引节点对象中
include/linux/fs.h
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 struct file { union { struct llist_node fu_llist ; struct rcu_head fu_rcuhead ; } f_u; struct path f_path ; #define f_dentry f_path.dentry struct inode *f_inode ; const struct file_operations *f_op ; spinlock_t f_lock; atomic_long_t f_count; unsigned int f_flags; fmode_t f_mode; loff_t f_pos; struct fown_struct f_owner ; const struct cred *f_cred ; struct file_ra_state f_ra ; u64 f_version; #ifdef CONFIG_SECURITY void *f_security; #endif void *private_data; #ifdef CONFIG_EPOLL struct list_head f_ep_links ; struct list_head f_tfile_llink ; #endif struct address_space *f_mapping ; #ifdef CONFIG_DEBUG_WRITECOUNT unsigned long f_mnt_write_state; #endif };
file_operations include/linux/fs.h
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 struct file_operations { struct module *owner ; loff_t (*llseek) (struct file *, loff_t , int ); ssize_t (*read) (struct file *, char __user *, size_t , loff_t *); ssize_t (*write) (struct file *, const char __user *, size_t , loff_t *); ssize_t (*aio_read) (struct kiocb *, const struct iovec *, unsigned long , loff_t ); ssize_t (*aio_write) (struct kiocb *, const struct iovec *, unsigned long , loff_t ); int (*readdir) (struct file *, void *, filldir_t ); unsigned int (*poll) (struct file *, struct poll_table_struct *) ; long (*unlocked_ioctl) (struct file *, unsigned int , unsigned long ); long (*compat_ioctl) (struct file *, unsigned int , unsigned long ); int (*mmap) (struct file *, struct vm_area_struct *); int (*open) (struct inode *, struct file *); int (*flush) (struct file *, fl_owner_t id); int (*release) (struct inode *, struct file *); int (*fsync) (struct file *, loff_t , loff_t , int datasync); int (*aio_fsync) (struct kiocb *, int datasync); int (*fasync) (int , struct file *, int ); int (*lock) (struct file *, int , struct file_lock *); ssize_t (*sendpage) (struct file *, struct page *, int , size_t , loff_t *, int ); unsigned long (*get_unmapped_area) (struct file *, unsigned long , unsigned long , unsigned long , unsigned long ) ; int (*check_flags)(int ); int (*flock) (struct file *, int , struct file_lock *); ssize_t (*splice_write)(struct pipe_inode_info *, struct file *, loff_t *, size_t , unsigned int ); ssize_t (*splice_read)(struct file *, loff_t *, struct pipe_inode_info *, size_t , unsigned int ); int (*setlease)(struct file *, long , struct file_lock **); long (*fallocate)(struct file *file, int mode, loff_t offset, loff_t len); int (*show_fdinfo)(struct seq_file *m, struct file *f); };
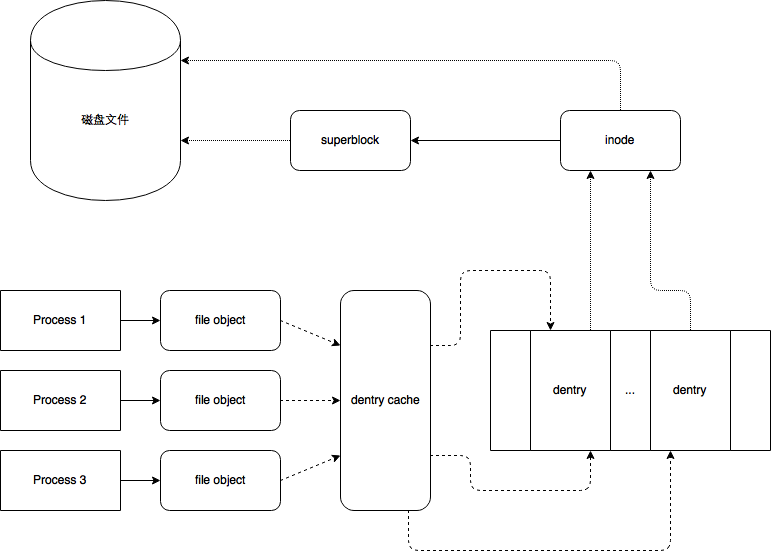
Dentry VFS把每一个目录看作由若干个目录和文件组成的一个普通文件。
*** 本来inode中应该包括“目录节点”的名称,但由于硬链接的存在,导致一个物理文件可能有多个文件名,因此把和“目录节点”名称相关的部分从 inode 中分开,放在一个专门的 dentry 结构(目录项)中 ***
在内存中, 每个文件都至少有一个dentry(目录项)和inode(索引节点)结构
dentry记录着文件名,上级目录等信息,正是它形成了我们所看到的树状结构
有关该文件的组织和管理的信息主要存放inode里面,它记录着文件在存储介质上的位置与分布
include/linux/fs.h
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 struct dentry { unsigned int d_flags; seqcount_t d_seq; struct hlist_bl_node d_hash ; struct dentry *d_parent ; struct qstr d_name ; struct inode *d_inode ; unsigned char d_iname[DNAME_INLINE_LEN]; unsigned int d_count; spinlock_t d_lock; const struct dentry_operations *d_op ; struct super_block *d_sb ; unsigned long d_time; void *d_fsdata; struct list_head d_lru ; struct list_head d_child ; struct list_head d_subdirs ; union { struct hlist_node d_alias ; struct rcu_head d_rcu ; } d_u; };
dentry的四种状态
空闲状态(Free)
未使用状态(unused)d_count为0,d_inode字段仍然指向关联的索引节点,目录对象包含有效的信息。为了在必要时回收内存,它的内容可能被丢弃。
正在使用状态(in use)d_count大于0,d_inode字段指向关联的索引节点,目录对象包含有效的信息,不能被丢弃。
负状态(negative)d_inode被置为NULL,该对象仍被保存在目录项高速缓存中,以便同一文件目录名的查找能够快速完成。
dentry_oprations include/linux/dcache.h
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 struct dentry_operations { int (*d_revalidate)(struct dentry *, unsigned int ); int (*d_weak_revalidate)(struct dentry *, unsigned int ); int (*d_hash)(const struct dentry *, const struct inode *, struct qstr *); int (*d_compare)(const struct dentry *, const struct inode *, const struct dentry *, const struct inode *, unsigned int , const char *, const struct qstr *); int (*d_delete)(const struct dentry *); void (*d_release)(struct dentry *); void (*d_prune)(struct dentry *); void (*d_iput)(struct dentry *, struct inode *); char *(*d_dname)(struct dentry *, char *, int ); struct vfsmount *(*d_automount )(struct path *); int (*d_manage)(struct dentry *, bool ); } ____cacheline_aligned;
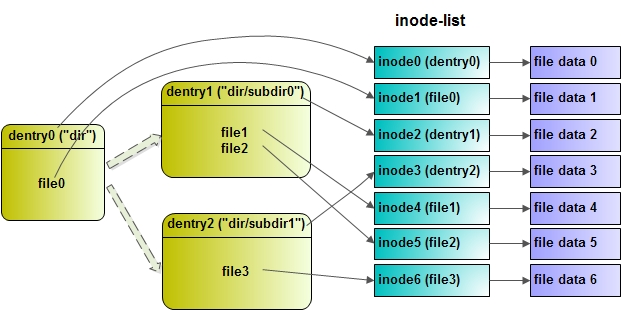
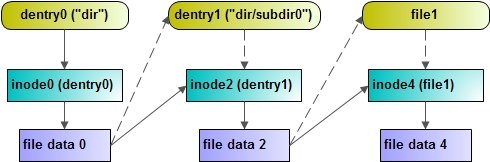
Dentry定位文件 首先,通过dir对应的dentry0找到inode0节点,有了inode节点就可以读取目录中的信息。其中包含了该目录包含的下一级目录与文件文件列表,包括name与inode号。
1 2 $ ls -i 975248 subdir0 975247 subdir1 975251 file0
然后,根据通过根据subdir0对应的inode号重建inode2,并通过文件数据(目录也是文件)与inode2重建subdir0的dentry节点:dentry1。
1 2 $ ls -i 975311 file1 975312 file2
接着,根据file1对应的inode号重建inode4,并通过文件数据与inode4重建file1的dentry节点。最后,就可以通过inode4节点访问文件了。
Dentry Cache 由于从硬盘读入一个目录项并构造相应的目录项对象需要花费大量的时间,也为了最大限度提高目处理这些录项对象的效率,VFS采用了dentry cache的设计。当有用户用ls命令查看某一个目录或用open命令打开一个文件时,VFS会为这里用的每个目录项与文件建立dentry项与inode,即“按需创建”。然后维护一个LRU(Least Recently Used)列表,当Linux认为VFS占用太多资源时,VFS会释放掉长时间没有被使用的dentry项与inode项。
这里的建立于释放是从内存占用的角度看。从Linux角度看,dentry与inode是VFS中固有的东西。所不同的只是VFS是否把dentry与inode读到了内存中。对于Ext2/3文件系统,构建dentry与inode的过程非常简单,但对于其他文件系统,则会慢得多。
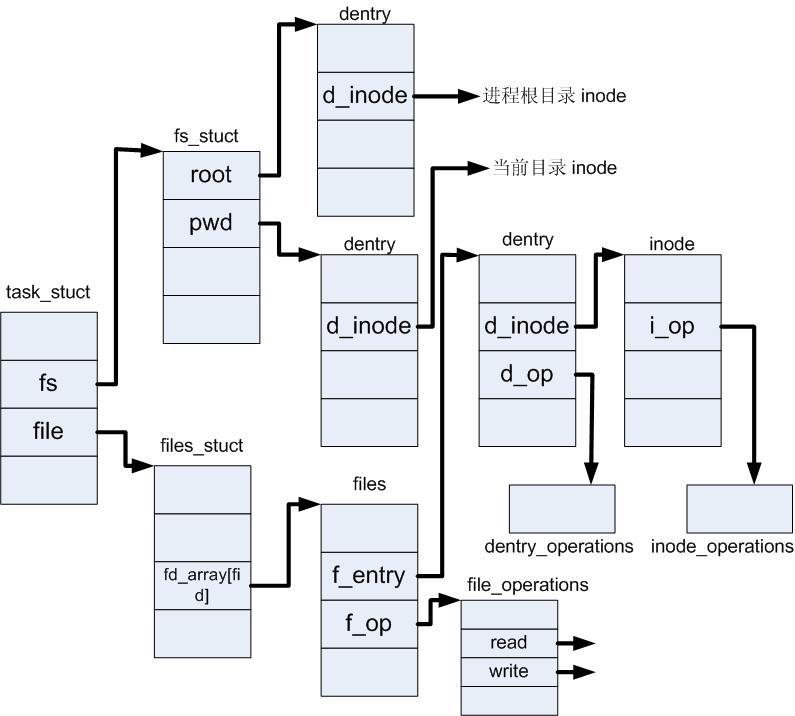
Process & File
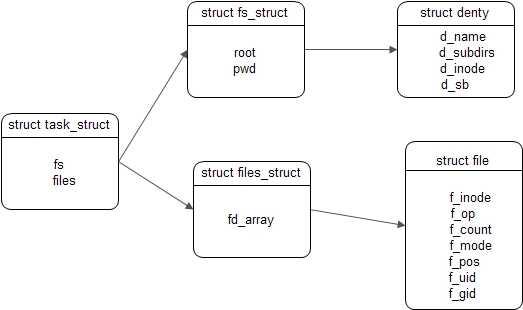
task_struct (include/linux/sched.h)
1 2 3 4 5 6 7 8 9 10 11 12 struct task_struct { ... struct thread_struct thread ; struct fs_struct *fs ; struct files_struct *files ; struct nsproxy *nsproxy ; ... };
进程控制块task_struct(include/linux/sched.h)中有两个变量与文件有关:fs(struct fs_struct)与files(struct files_struct)。
fs_struct (include/linux/fs_struct.h)
1 2 3 4 5 6 7 8 struct fs_struct { int users; spinlock_t lock; seqcount_t seq; int umask; int in_exec; struct path root , pwd ; };
path (include/liinux/path.h)
1 2 3 4 struct path { struct vfsmount *mnt ; struct dentry *dentry ; };
fs中存储着root与pwd两个指向dentry项的指针。用户定路径时,绝对路径会通过root进行定位;相对路径会通过pwd进行定位。进程的root不一定是文件系统的根目录。如ftp进程的根目录不是文件系统的根目录,这样才能保证用户只能访问ftp目录下的内容。files是一个file object列表,其中每一个节点对应着一个被打开了的文件。
files_struct (include/linux/fdtable.h)
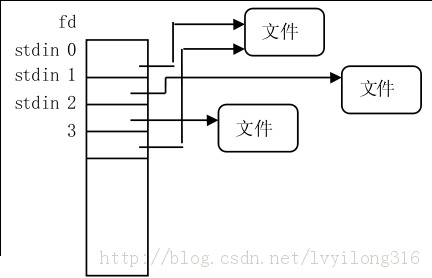
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 struct files_struct { atomic_t count; struct fdtable __rcu *fdt ; struct fdtable fdtab ; spinlock_t file_lock ____cacheline_aligned_in_smp; int next_fd; unsigned long close_on_exec_init[1 ]; unsigned long open_fds_init[1 ]; struct file __rcu * fd_array [NR_OPEN_DEFAULT ]; };
当进程定位到文件时,会构造一个file object,并通过f_inode关联到inode节点。文件关闭时(close),进程会释放对应对应file object。
fdtable (include/linux/fdtable.h)
1 2 3 4 5 6 7 struct fdtable { unsigned int max_fds; struct file __rcu **fd ; unsigned long *close_on_exec; unsigned long *open_fds; struct rcu_head rcu ; };
fd数组第一个元素[0]是进程的标准输入文件;第二个元素[1]是进程的标准输出文件;第三个元素[2]是进程的标准错误文件。
文件系统类型 特殊文件系统
文件系统
安装点
说明
bdev
无
块设备
binfmt_misc
任意
其他可执行格式
devpts
/dev/pts
伪终端支持
eventpollfs
无
由事件轮询机制使用
futexfs
无
由futex(快速用户空间加锁)机制使用
pipefs
无
管道
proc
/proc
对内核数据结构的常规访问点
rootfs
无
为启动阶段提供一个空的根目录
shm
无
IPC共享线性区
mqueue
任意
实现POSIX消息队列时使用
sockfs
无
套接字
sysfs
/sys
对系统数据的常规访问点
tmpfs
任意
临时文件(若不被交换出去,则常驻内存中)
usbfs
/proc/bus/usb
USB设备
内核给每个安装的特殊文件系统分配一个虚拟的块设备,让其主设备号为0,次设备号有任意值(每个特殊的文件系统有不同的值)
文件系统类型注册 文件系统的源码要么包含在内核映像中,要么作为一个模块被动态装入。每个注册的文件系统都用一个类型为file_system_type的对象来表示。include/linux/fs.h)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 struct file_system_type { const char *name; int fs_flags; #define FS_REQUIRES_DEV 1 #define FS_BINARY_MOUNTDATA 2 #define FS_HAS_SUBTYPE 4 #define FS_USERNS_MOUNT 8 #define FS_USERNS_DEV_MOUNT 16 #define FS_RENAME_DOES_D_MOVE 32768 struct dentry *(*mount ) (struct file_system_type *, int , const char *, void *); void (*kill_sb) (struct super_block *); struct module *owner ; struct file_system_type * next ; struct hlist_head fs_supers ; struct lock_class_key s_lock_key ; struct lock_class_key s_umount_key ; struct lock_class_key s_vfs_rename_key ; struct lock_class_key s_writers_key [SB_FREEZE_LEVELS ]; struct lock_class_key i_lock_key ; struct lock_class_key i_mutex_key ; struct lock_class_key i_mutex_dir_key ; };
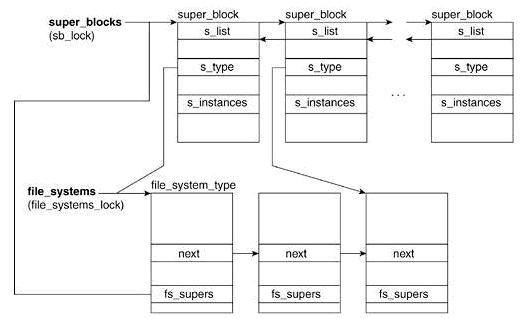
所有文件系统类型的对象都插入道一个单向链表中,由变量file_systems指向链表的第一个元素,file_systems->next指向链表的下一个元素。
int register_filesystem(struct file_system_type * fs)[fs/filesystems.c]file_systems列表中查找受否与传入fs->name同名的文件系统,如果存在则返回找到的fs,若不存在将传入文件系统fs加入file_systems列表
对比一下ramfs_fs_type和root_fs_type
1 2 3 4 5 6 7 8 9 10 11 static struct file_system_type ramfs_fs_type = .name = "ramfs" , .mount = ramfs_mount, .kill_sb = ramfs_kill_sb, .fs_flags = FS_USERNS_MOUNT, }; static struct file_system_type rootfs_fs_type = .name = "rootfs" , .mount = rootfs_mount, .kill_sb = kill_litter_super, };
发现fs_flags = FS_USERNS_MOUNT,这个flag似乎想告诉我们,ramfs是挂载到用户命名空间的,言外之意rootfs不是挂载到用户空间的,那便是内核空间喽。
文件系统处理
每个文件系统都有自己的根目录
已安装文件系统的根目录隐藏了父文件系统的安装点目录原来的内容
命名空间 通常进程共享一个命名空间,位于系统的根文件系统且被init进程使用的已安装文件系统树。如果clone()系统调用以CLONE_NEWNS标志创建一个新进程,那么新进程将获取一个新的命名空间,新进程再创建的新新进程将继承新命名空间。
fork
vfork
clone
KeyPoint 启动流程
start_kernel[init/main.c]
vfs_caches_init(totalram_pages)[fs/dcache.c]
dcache_init()[fs/dcache.c]dentry_cache和dentry_hashtable
inode_init()[fs/inode.c]inode_cachep和inode_hashtable
files_init()[fs/file_table.c]file_cachep、files_stat.max_files
mnt_init()[fs/namespace.c]mnt_cache,mount_hashtable,mountpoint_hashtable
sysfs_init()[fs/sysfs/mount.c]sysfs_dir_cachepbdi_init(&sysfs_backing_dev_info)register_filesystem(&sysfs_fs_type)sysfs_mnt = kern_mount(&sysfs_fs_type)
init_root()[fs/ramfs/inode.c]bdi_init(&ramfs_backing_dev_info)register_filesystem(&rootfs_fs_type)
init_mount_tree()[fs/namespace.c]/ mnt = vfs_kern_mount(type, 0, "rootfs", NULL)ns = create_mnt_ns(mnt)init_task(PID=0)命名空间 init_task.nsproxy->mnt_ns = nspwd和root set_fs_pwd(current->fs, &root); set_fs_root(current->fs, &root);
bdev_cache_init()[fs/block_dev.c]bdev_cachep
mount bdev
chrdev_init()[fs/char_dev.c]cdev_map
Mount文件系统
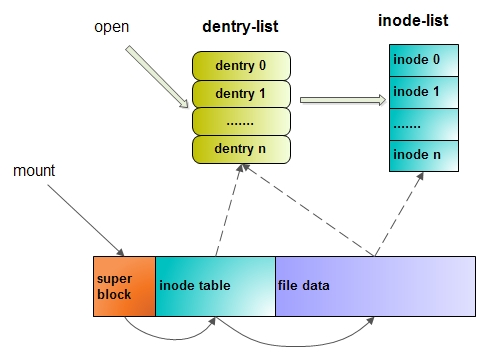
mount时,linux先找到磁盘分区的super block,然后通过解析磁盘的inode table与file data,构建出自己的dentry列表与inode列表。需要注意的是,VFS实际上是按照Ext的方式进行构建的,所以两者非常相似(毕竟Ext是Linux的原生文件系统)。比如inode节点,Ext与VFS中都把文件管理结构称为inode,但实际上它们是不一样的。Ext的inode节点在磁盘上;VFS的inode节点在内存里。Ext-inode中的一些成员变量其实是没有用的,如引用计数等。保留它们的目的是为了与vfs-node保持一致。这样在用ext-inode节点构造vfs-inode节点时,就不需要一个一个赋值,只需一次内存拷贝即可。
参考&鸣谢