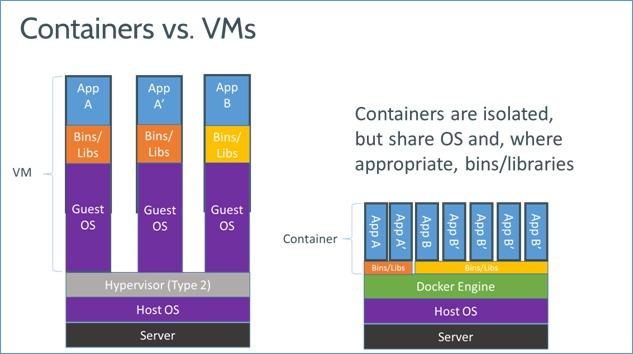
Deploy Linux部署 (由于Linux发行版众多,本文以RHEL7.2为例)
单机版环境docker部署 通过yum源安装docker,yum install docker。
安装完成后,使用docker version查看docker客户端和服务端版本号
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 $ docker version Client: Version: 1.12.5 API version: 1.24 Go version: go1.6.4 Git commit: 7392c3b Built: Fri Dec 16 02:23:59 2016 OS/Arch: linux/amd64 Server: Version: 1.12.5 API version: 1.24 Go version: go1.6.4 Git commit: 7392c3b Built: Fri Dec 16 02:23:59 2016 OS/Arch: linux/amd64
分布式环境docker部署 详细请见:docker官网关于linux环境安装部分
MacOS部署 从Docker官网上下载Docker.dmg(下载地址:https://www.docker.com/products/docker#/mac),并安装。
安装完成后,使用docker version查看docker客户端和服务端版本号
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 $ docker version Client: Version: 1.12.5 API version: 1.24 Go version: go1.6.4 Git commit: 7392c3b Built: Fri Dec 16 06:14:34 2016 OS/Arch: darwin/amd64 Server: Version: 1.12.5 API version: 1.24 Go version: go1.6.4 Git commit: 7392c3b Built: Fri Dec 16 06:14:34 2016 OS/Arch: linux/amd64
Container 容器创建&删除 docker create 使用docker create {选项} {镜像ID/镜像名称} {COMMAND}创建容器,返回容器ID
1 2 $ docker create -i -t --name=ubu my_ubuntu_03 /bin/bash 1af8ed9b04f8b16d264418038e1f4004b1f5512f229059646a5c9b1d20ed8404
docker run 使用docker run {选项} {镜像ID/镜像名称} {COMMMAND}创建并运行容器,run = create + start。
1 docker run -i -t ubuntu /bin/bash
docker rm 使用docker rm {容器ID/容器名称}删除已经停止的容器,使用-f参数,可删除正在运行中的容器。
容器查询 docker ps 使用docker ps列出所有运行中的容器,带-a参数,可列出所有容器(包括非运行状态的容器)
1 2 3 4 5 6 7 $ docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 1af8ed9b04f8 my_ubuntu_03 "/bin/bash" 2 minutes ago Up 3 seconds ubu ebe0ce381aaf my_ubuntu_03 "/usr/sbin/sshd -D" 42 hours ago Up 42 hours 0.0.0.0:50022->22/tcp ubu_03_sshd e69e9d4cdfa3 my_ubuntu_01 "/bin/bash" 43 hours ago Exited (0) 42 hours ago ubu_01 0fa200a32e8e ceph/daemon "/entrypoint.sh osd" 47 hours ago Up 47 hours ceph-osd be0583fade06 ceph/daemon "/entrypoint.sh mon" 4 days ago Up 47 hours ceph-mon
docker inspect 使用docker inspect {容器ID/容器名称}查看容器详细信息(容器详细信息以JSON格式返回)
1 2 3 4 5 6 7 8 9 10 11 $ docker inspect ubu_03_sshd [ { "Id": "ebe0ce381aafa73ec679ec0dc38e8d54291378693146a65d3655dd574c76ec01", "Created": "2016-12-26T08:00:56.73955094Z", "Path": "/usr/sbin/sshd", "Args": [ "-D" ], ...... ]
容器启停 使用docker start/stop {容器ID/容器名称}启动或停止容器运行。
容器访问 在容器内执行命令 1 2 3 4 $ docker exec ubu ps -ef UID PID PPID C STIME TTY TIME CMD root 1 0 0 07:01 ? 00:00:00 /bin/bash root 10 0 0 07:02 ? 00:00:00 ps -ef
Attach/Detach容器 1 2 $ docker attach ubu root@1af8ed9b04f8:/#
Detach容器时,只要在command line中输入exit即可,但detach时,会导致容器停止运行。所以若不想导致容器停止运行可以使用docker exec -it ubu /bin/bash
Image 镜像创建 创建新镜像(Dockerfile) 使用Dockerfile创建镜像,首先需要选择基础镜像,然后撰写dockerfile,最后使用docker build -t {new image name}:{new image tag} [-f {dockerfile}] .创建Image
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 $ docker build -t new_image_ubu03:v1 -f ./dockerfile/tmp.docker . Sending build context to Docker daemon 317.7 MB Step 1 : FROM my_ubuntu_03 ---> 28b69113a240 Step 2 : MAINTAINER xxx xx "x.xxx@xxxx.com" ---> Running in ae3004ef2bd2 ---> 68ab9a056fbf Removing intermediate container ae3004ef2bd2 Successfully built 68ab9a056fbf $ docker images REPOSITORY TAG IMAGE ID CREATED SIZE new_image_ubu03 v1 68ab9a056fbf 14 seconds ago 304.4 MB my_ubuntu_01 v1 e1aace2f9532 46 hours ago 304.4 MB my_ubu base 31184d4c3c2c 47 hours ago 317.7 MB my_ubuntu_03 latest 28b69113a240 3 days ago 304.4 MB my_ubuntu_01 latest 800c37009cde 3 days ago 270 MB ubuntu latest 104bec311bcd 2 weeks ago 128.9 MB ceph/daemon latest c06ccf521c4e 6 weeks ago 1.078 GB
关于dockerfile的撰写请见《Dockerfile》
基于已有镜像创建新镜像 使用docker commit {容器名称/容器ID} {RESPOSITORY}<TAG>用已有容器创建镜像。
1 2 $ docker commit ubu_01 my_ubuntu_01:v1 sha256:e1aace2f953280326b96f31708ddf8f9f02289845e997736fcb1d0342777c72f
从docker hub上下载新镜像 在docker hub上有很多镜像,供使用者下载,用户可以使用docker search查询要下载的镜像,然后使用docker pull下载镜像。
1 2 3 4 5 $ docker pull hello-world Using default tag: latest latest: Pulling from library/hello-world Digest: sha256:0256e8a36e2070f7bf2d0b0763dbabdd67798512411de4cdcf9431a1feb60fd9 Status: Image is up to date for hello-world:latest
镜像查询 查询本地镜像 1 2 3 4 5 6 7 8 $ docker images REPOSITORY TAG IMAGE ID CREATED SIZE my_ubu base 31184d4c3c2c 7 seconds ago 317.7 MB my_ubuntu_03 latest 28b69113a240 47 hours ago 304.4 MB my_ubuntu_01 latest 800c37009cde 2 days ago 270 MB ubuntu latest 104bec311bcd 12 days ago 128.9 MB ceph/daemon latest c06ccf521c4e 5 weeks ago 1.078 GB hello-world latest c54a2cc56cbb 5 months ago 1.848 kB
查询镜像详细信息 使用docker inspect {IMAGE ID/REPOSITORY}<:{TAG}>查询镜像库的详细信息,TAG默认为“latest”。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 $ docker inspect my_ubu:base [ { "Id": "sha256:31184d4c3c2cbbc56e087dfff68cad2d2d89d628a260f6789baf108345cd6c9b", "RepoTags": [ "my_ubu:base" ], "RepoDigests": [], "Parent": "", "Comment": "Imported from -", "Created": "2016-12-28T07:30:31.500350508Z", "Container": "", "ContainerConfig": { ...... ]
查询hub上的镜像 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 $ docker search ceph NAME DESCRIPTION STARS OFFICIAL AUTOMATED ceph/daemon Image containing all the Ceph daemons 29 [OK] ceph/demo 10 [OK] ceph/osd Ceph OSD (object storage daemon) 6 [OK] ceph/base Ceph base image 5 [OK] ceph/radosgw Ceph RADOSGW (S3/Swift-like service for Ceph) 4 [OK] cdxvirt/ceph-daemon All-in-one container for cdxvirt ceph core... 2 [OK] ceph/config Ceph bootstrap (configuration) 2 [OK] ceph/rbd Ceph rbd (RADOS block device) CLI tool 2 [OK] ceph/mds Ceph MDS (metadata server) 2 [OK] ulexus/ceph-osd DEPRECATED: development is now at ceph/osd 2 [OK] ceph/mon Ceph MON (monitor daemon) 1 [OK] h0tbird/ceph Containerized Ceph distributed file system 1 [OK] ceph/rados Ceph rados (reliable autonomic distributed... 1 [OK] cdxvirt/ceph-base Ceph base container image 1 [OK] qnib/ceph-base QNIBTerminal ceph base image 0 [OK] qnib/ceph-mono Monolithic approach of an CEPH cluster + r... 0 [OK] fernandosanchez/ceph-dash ceph-dash 0 [OK] ceph/install-utils Install wrappers for common Ceph utility p... 0 [OK] qnib/ceph-mon QNIBTerminal CEPH monitoring Image 0 [OK] cephbuilder/ceph Docker image for building custom Ceph daem... 0 [OK] qnib/d-ceph-fuse QNIBTerminal image (debian) mounting /ceph... 0 [OK] ulexus/ceph-mon DEPRECATED: development is now at ceph/mon 0 [OK] fmeppo/ceph-daemon Main container for Ceph in Docker. 0 [OK] fmeppo/ceph-base Base container for Ceph in Docker. 0 [OK] xenopathic/ceph-keystone Automated full-stack Ceph environment with... 0 [OK]
镜像删除 使用docker rmi {REPOSITORY/IMAGE ID}删除镜像。
1 2 3 4 5 $ docker rmi hello-world Untagged: hello-world:latest Untagged: hello-world@sha256:0256e8a36e2070f7bf2d0b0763dbabdd67798512411de4cdcf9431a1feb60fd9 Deleted: sha256:c54a2cc56cbb2f04003c1cd4507e118af7c0d340fe7e2720f70976c4b75237dc Deleted: sha256:a02596fdd012f22b03af6ad7d11fa590c57507558357b079c3e8cebceb4262d7
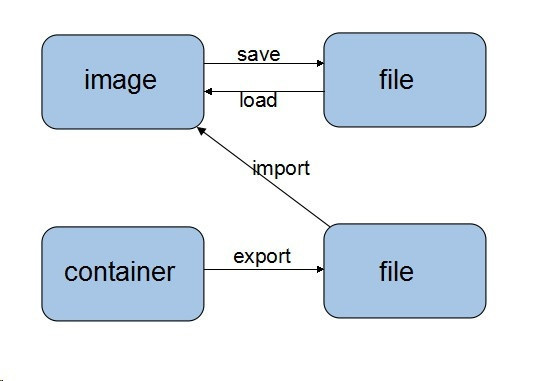
镜像导出导入 save & load 只用于镜像(image)的导入导出文件
export & import
export用于容易导出成文件
import用于文件导入成镜像(image)
关系图
Volume 数据卷创建、删除、查询、权限 创建&权限 *** docker在创建容器时,可以创建数据卷;一旦容器运行后,就不能动态添加数据卷。若想添加需要重新创建容器。***
私有数据卷创建 在docker run/create时,使用-v {容器内路径}参数在容器内创建指定的目录,并映射到其宿主机/var/lib/docker/volumes/{ID}/_data的路径下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 # 数据卷创建 $ docker run -it --name=ubu2 -v=/home/zhoub/docker/data ubuntu /bin/bash # 数据卷查询 $ dccker inspect ubu2 ... "Mounts": [ { "Name": "95868b7e6fd47927cfb7f54b35057545f4302d69ed92aa73425dffc289527b6b", "Source": "/var/lib/docker/volumes/95868b7e6fd47927cfb7f54b35057545f4302d69ed92aa73425dffc289527b6b/_data", "Destination": "/home/zhoub/docker/data", "Driver": "local", "Mode": "", "RW": true, "Propagation": "" } ], ...
共享数据卷创建 在docker run/create时,使用-v {宿主机路径:容器内路径:访问权限(ro/rw,默认是RW)}参数挂载数据目录或文件到容器内,宿主机与容器共享该目录,无论宿主机还是容器修改该目录后,另一方也能看到改变。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 # 数据卷创建 $ docker run -it --name=ubu -v=/home/zhoub/docker/data:/data ubuntu /bin/bash # 数据卷查询 $ docker inspect ubu ... "Mounts": [ { "Source": "/home/zhoub/docker/data", "Destination": "/data", "Mode": "", "RW": true, "Propagation": "rprivate" } ], ...
数据卷删除
仅使用docker rm删除容器,会导致数据卷无法删除,仍占用硬盘空间
使用docker rm -v删除容器和数据卷
数据卷容器 创建数据卷容器 1 $ docker run -v /vol --name voldata ubuntu echo "Data Container"
或
1 $ docker create -v /vol --name voldata ubuntu echo "Data Container"
注:
数据卷容器不需要运行,运行会白浪费系统资源
不要下载微小镜像创建数据卷容器,只使用本机所带的镜像即可,不需要咱用额外的存储空间。
使用数据卷容器 在docker run中使用--volumes-from参数为新建的容器挂载voldata数据卷容器中的/vol目录
1 $ docker run --volumes-from voldata -it --name testContainer ubuntu /bin/bash
数据卷备份 将数据卷容器中数据卷里的数据备份到指定目录中
步骤:
创建备份目录
创建容器映射备份目录到容器内,并挂载数据卷容器
在容器中将数据卷容器中的数据copy到映射的备份目录内
1 2 3 $ mkdir /tmp/backup$ docker run --rm --volumes-from voldata -v /tmp/backup:/backup ubuntu tar cvf /backup/voldata.tar /vol
看到此处估计你已经要骂娘了,什么破Docker,连个卷管理接口都没有!以上是老版本中docker对卷的管理方法。接下来说一下新版本中docker对卷的管理。
新的数据卷管理
卷创建docker volume create {options},创建卷,可指定卷名称和访问卷所使用的驱动。目前docker volume plugin支持的驱动包括:blockbridge、convoy、flocker、glusterfs、horcrux、ipfs、netshare、openstorage、quobyte
卷查询docker volume ls,显示卷列表docker volume inspect {volume name},显示指定卷的详细信息
卷删除docker rm {volume name},删除指定卷,若卷已经被容器所加载,无论容器是否出于运行状态,删除都会失败。
*** 很可惜docker新版本中还是不支持动态加载卸载数据卷 ***
Network docker 有三种网络bridge、host、none。
bridge 桥接网络
host 复制宿主机网络
none 无网络,容器只有一个回环地址
网络管理 网络创建 bridge 可通过docker network create --subnet {CIDR} {network name}创建bridge网络
host 默认docker会提供一个host网络,用户不能再手动创建该网络Error response from daemon: only one instance of "host" network is allowed
none 该网络不可自创建
网络删除 可使用docker network rm {network name}删除指定网络
网络查询 使用docker network ls查看网络列表
1 2 3 4 5 6 $ docker network ls ETWORK ID NAME DRIVER SCOPE 852c90cb4a48 bridge bridge local bebda2efe6dc host host local 6a69c0cd935e my_net bridge local 09cf35b0a2fe none null local
使用docker network inspect {network name}查看指定网络信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 $ docker network inspect my_net [ { "Name": "my_net", "Id": "6a69c0cd935ef315d143f1253634b8cce2b20e8e330ce791d53d26a6a08c387f", "Scope": "local", "Driver": "bridge", "EnableIPv6": false, "IPAM": { "Driver": "default", "Options": {}, "Config": [ { "Subnet": "192.168.100.0/24", "Gateway": "192.168.100.1" } ] }, "Internal": false, "Containers": {}, "Options": { "com.docker.network.bridge.name": "my_net" }, "Labels": {} } ]
网络使用 with ‘–network’ 在docker create/run时,指定--network {network name}参数,默认网络使用bridge。
1 $ docker run -it --name net_1 --network my_net my_ubuntu_03 /bin/bash
container复制 使用--network container:{容器名称/容器ID}将指定容器的网络及主机名复制到新容器内。
创建‘net_4’容器,并复制‘net_1’的network
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 $ docker run -it --name net_4 --network container:net_1 my_ubuntu_03 /bin/bash root@5eb98cff1ec6:/# ifconfig eth0 Link encap:Ethernet HWaddr 02:42:c0:a8:64:02 inet addr:192.168.100.2 Bcast:0.0.0.0 Mask:255.255.255.0 inet6 addr: fe80::42:c0ff:fea8:6402/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:8 errors:0 dropped:0 overruns:0 frame:0 TX packets:8 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:648 (648.0 B) TX bytes:648 (648.0 B) lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0 inet6 addr: ::1/128 Scope:Host UP LOOPBACK RUNNING MTU:65536 Metric:1 RX packets:0 errors:0 dropped:0 overruns:0 frame:0 TX packets:0 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
容器‘net_1’的网卡信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 $ docker exec -it net_1 /bin/bash root@5eb98cff1ec6:/# ifconfig eth0 Link encap:Ethernet HWaddr 02:42:c0:a8:64:02 inet addr:192.168.100.2 Bcast:0.0.0.0 Mask:255.255.255.0 inet6 addr: fe80::42:c0ff:fea8:6402/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:16 errors:0 dropped:0 overruns:0 frame:0 TX packets:16 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:1395 (1.3 KB) TX bytes:1284 (1.2 KB) lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0 inet6 addr: ::1/128 Scope:Host UP LOOPBACK RUNNING MTU:65536 Metric:1 RX packets:4 errors:0 dropped:0 overruns:0 frame:0 TX packets:4 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:375 (375.0 B) TX bytes:375 (375.0 B)
Docker Remote API 开启Remote API 以RHEL7.2为例,开启Docker Remote API服务
修改systemd中的docker.serverExecStart项,增加-H tcp://0.0.0.0:2375允许任意客户端访问;增加-H unix:///var/run/docker.sock保证docker命令能正常使用。--tls=true --tlscert=cert.pem --tlskey=key.pem。详细请见
增加防火墙规则/关闭防火墙firewalld。sudo systemctl stop firewalld
重启docker服务sudo systemctl daemon-reloadsudo systemctl restart docker
API使用说明 详细请见:《Docker Remote API v1.24》
参考&鸣谢