Ceph号称统一存储,何为统一,就是将块、文件、对象统一到一起。RadosGW(简称RGW)就是Ceph中提供对象存储服务的模块。它能提供S3和Swift两种对象存储接口,当然也是最主流的两种接口。
本文不打算介绍概念性的东西,只为扒一扒RGW的架构。废话不多讲,直接上图
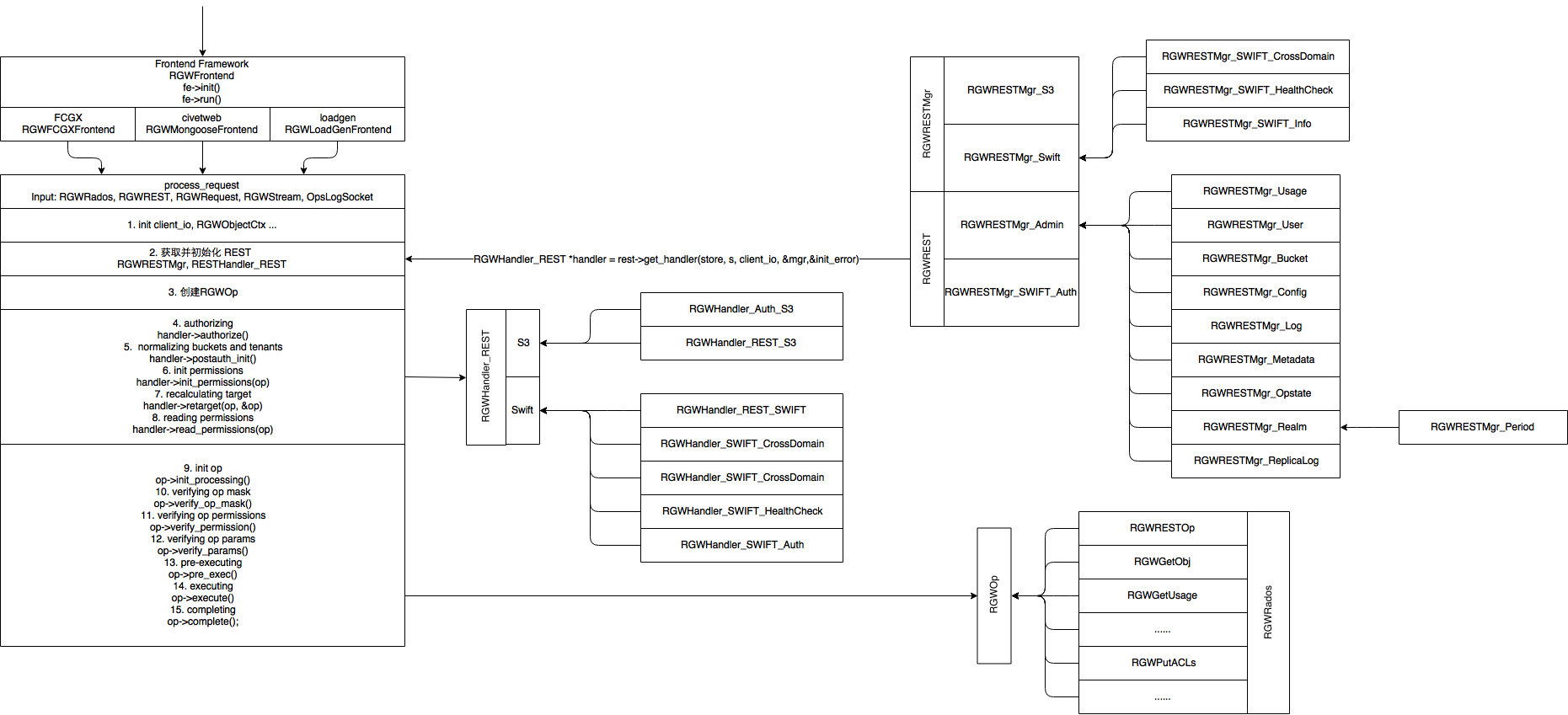
我觉得画的挺清楚了,就不细讲了。
一张图不过瘾,再来一发。
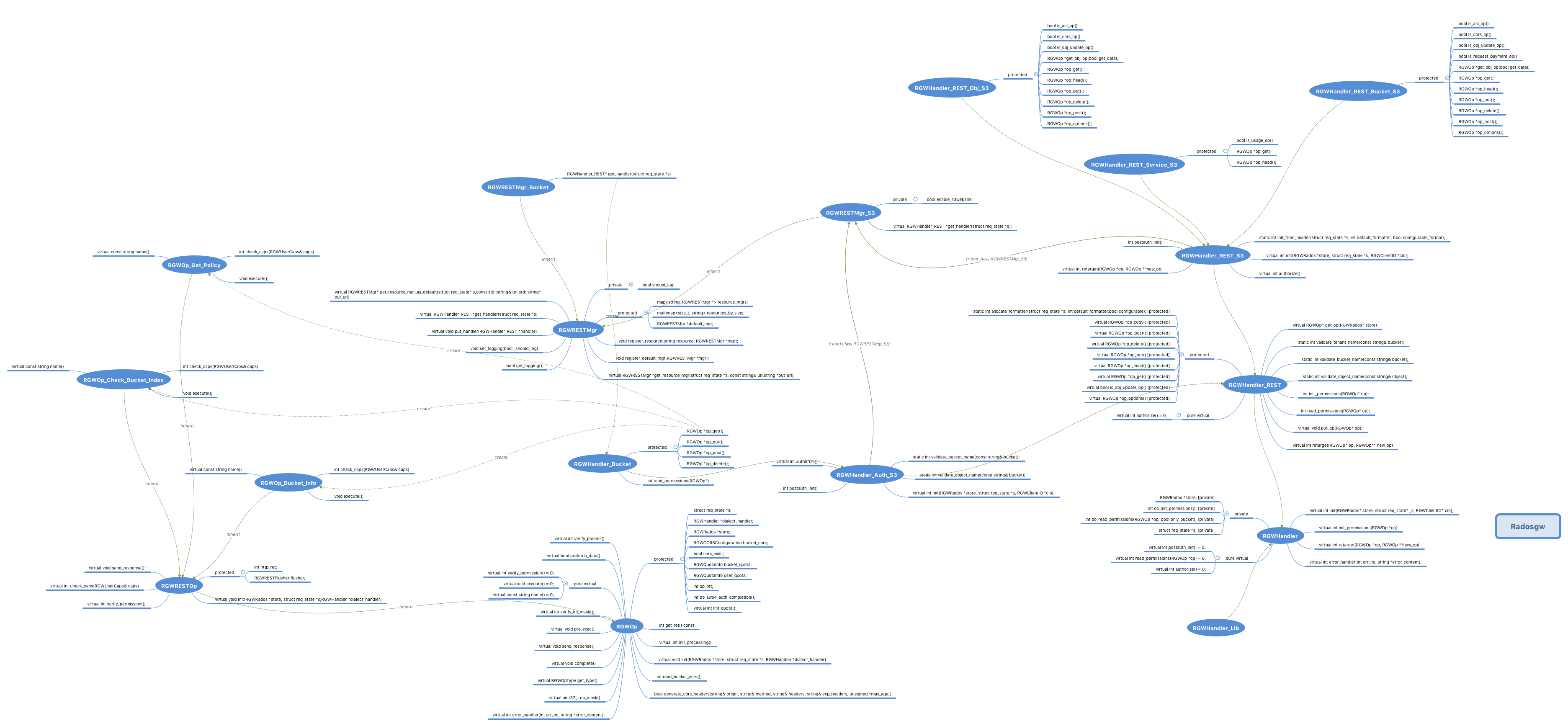
Ceph号称统一存储,何为统一,就是将块、文件、对象统一到一起。RadosGW(简称RGW)就是Ceph中提供对象存储服务的模块。它能提供S3和Swift两种对象存储接口,当然也是最主流的两种接口。
本文不打算介绍概念性的东西,只为扒一扒RGW的架构。废话不多讲,直接上图
我觉得画的挺清楚了,就不细讲了。
一张图不过瘾,再来一发。
DNSmasq是一个小巧且方便地用于配置DNS和DHCP的工具,适用于小型网络,它提供了DNS功能和可选择的DHCP功能。它服务那些只在本地适用的域名,这些域名是不会在全球的DNS服务器中出现的。DHCP服务器和DNS服务器结合,并且允许DHCP分配的地址能在DNS中正常解析,而这些DHCP分配的地址和相关命令可以配置到每台主机中,也可以配置到一台核心设备中(比如路由器),DNSmasq支持静态和动态两种DHCP配置方式。
在rhel7.4上的安装yum install -y dnsmasq, 完成dnsmasq的安装同时也推荐安装bind-utils,这个包提供很多dns测试相关工具yum install -y bind-utils, 如dig、nslookup
创建两个dnsmasq节点,一个做base dns,一个做upper dns
base dns的dnsmasq.conf配置:
1 | listen-address=172.17.0.2,127.0.0.1 |
*** 在使用CNAME时,<target>必须本机可访问对象,所以此处我将rhel82放到/etc/hosts中 ***
base dns的/etc/hosts配置:
1 | 127.0.0.1 localhost |
upper dns配置:
1 | address=/myweb.dockxen.mydns/192.168.1.82 |
完成base dns和upper dns的配置后使用dnsmasq -d debug模式启动,可以看到部分调试信息
测试验证需要安装bind-utils,测试中会用到其中的dig和nslookup,开始测试前修改/etc/resolv.conf中的nameserver 172.17.0.2
1 | [root@dnclient /]# dig myweb.dockxen.mydns |
1 | [root@dnclient /]# dig web.dockxen.dns |
1 | [root@dnclient /]# dig +noall +answer SRV _ldap._tcp.dockxen.mydns |
etcd各个节点之间的通讯使用域名方式访问,由于etcd节点ip地址可以以dhcp方式获取,每次etcd节点重启都有可能导致访问地址发生变化。若使用/etc/hosts文件进行“域名-ip”映射涉及到/etc/hosts文件同步分发问题,所以使用dnsmasq来完成“域名-ip”的映射。
关于etcd的服务发现配置请见参考&鸣谢
Matplotlib数据可视化第三方库(官网)。由各种可视化类构成。
matplotlib.pyplot是绘制各类可视化图形的命令子库。
1 | #!/usr/bin/python |
plt.plot(x,y,format_string, **kwargs)
format_string分别由“颜色字符”、“风格字符”、“标记字符”构成
** 颜色字符 **
| 颜色字符 | 说明 | 颜色字符 | 说明 |
|---|---|---|---|
| ‘b’ | 蓝色 | ‘m’ | 洋红色 |
| ‘g’ | 绿色 | ‘y’ | 黄色 |
| ‘r’ | 红色 | ‘k’ | 黑色 |
| ‘c’ | 青色 | ‘w’ | 白色 |
| ‘#008000’ | RGB某颜色 | ‘0.8’ | 灰度值字符串 |
如果用户不指定颜色,系统会自动指定不重复的颜色。
** 风格字符 **
| 风格字符 | 说明 |
|---|---|
| ‘-‘ | 实现 |
| ‘–’ | 破折线 |
| ‘-.’ | 点划线 |
| ‘:’ | 虚线 |
| ‘’ | 无线条 |
*** 更多关于标记内容请见HERE ***
1 | import numpy as np |
plt.subplot(nrows, ncols, plot_number) 将绘制区域分割成 nrows x ncols个区域,plot_number指定绘制的是哪个区域
1 | import numpy as np |
图像采用的色彩模式为RGB模式,即每个像素点由R(红色)、G(绿色)、B(蓝色)组成。我们人眼所能看到的颜色都是由这三种颜色变化叠加得到的。
图像是一个由像素组成的二维矩阵,每个元素是一个RGB值。
OSX: pip install pillow

1 | from PIL import Image |
1 | md_img = [255,255,255] - img |

1 | md_img = 255 - img_l |

1 | md_img = (100.0/255.0)*img_l + 150 |

1 | md_img = 255 * ((img_l/255.0)**2) |

1 | img_l_float = img_l.astype("float") |
无光源效果:
有光源效果:
1 | save_img = Image.fromarray(md_img.astype('uint8')) |
NumPy是一个开源的Python科学计算基础库
OSX: pip install numpy
| 属性 | 描述 |
|---|---|
| ndim | 维度的数量 |
| shape | 矩阵的行列数 |
| size | 数组元素个数 |
| dtype | 数组元素的类型 |
| itemsize | 数组元素的大小 |
1 | import numpy as np |
*** ndarray数组可以由非同质对象构成,非同质ndarray元素为对象类型。非同质ndarray对象无法有效发挥NumPy优势,应尽量避免使用。 ***
1 | b = np.array([[1,2,3],[1,2]]) |
| 数据类型 | 描述 |
|---|---|
| bool | 布尔类型 True or False |
| intc | 与C语言中的int一致 |
| intp | 与C语言中的size_t一致 |
| int8 | 8位长度的整数[-128,127] |
| int16 | 16位长度的整数[-32768,32767] |
| int32 | 32位长度的整数[-231,231-1] |
| int64 | 64位长度的整数[-263,263-1] |
| uint8 | 8位无符合整数 |
| uint16 | 16位无符号整数 |
| uint32 | 32位无符号整数 |
| uint64 | 64位无符号整数 |
| float16 | 16位半精度浮点数 |
| float32 | 32位半精度浮点数 |
| float64 | 64位半精度浮点数 |
| complex64 | 复数类型,实部和虚部都是32位浮点数 |
| complex128 | 复数类型,实部和虚部都是64位浮点数 |
np.array(list/tuple) or np.array(list/tuple, dtype=np.float32)当np.array不指定dtype时,NumPy将根据数据情况关联一个dtype类型。
| 函数 | 描述 |
|---|---|
| np.arange(n) | 返回一个从0到n-1的整数类型数组 |
| np.ones(shape) | 根据shape生成一个全1的数组 |
| np.zeros(shape) | 根据shape生成一个全0的数组 |
| np.full(shape,val) | 根据shape生成一个全val的数组 |
| np.eye(n) | 返回一个n*n的数组,对角线为1,其余为0 |
| np.ones_like(a) | 根据数组a的shape生成一个全1的数组 |
| np.zeros_like(a) | 根据数组a的shape生成一个全0的数组 |
| np.full_like(a,val) | 根据数组a的shape生成一个全val的数组 |
| np.linspace() | 根据起止数据等间距的填充数据,形成数组 |
| np.concatenate() | 将两个或多个数组合并成一个新的数组 |
1 | d = np.arange(10) |
ones,zeros生成的数组元素都是浮点数类型(float64),而full生成的是整数类型。若想要ones和zeros也生成整数类型,增加参数dtype=np.int64
1 | print np.zeros((3,4)) |
1 | c = np.eye(5) |
1 | print np.linspace(1,10,4) |
endpoint表示最后一个元素10是否作为最后一个元素出现
1 | print np.concatenate((c,c)) |
| 函数 | 描述 |
|---|---|
| .reshape(shape) | 不改变数组元素,返回一个shape形状的数组,原数组不变 |
| .resize(shape) | 与reshape功能一般,但修改原数组 |
| .swapaxes(ax1,ax2) | 将数组n个维度中的两个维度进行调换 |
| .flatten() | 对数组进行降维,返回一维数组,原数组不变 |
1 | f = np.ones((2,3,4)) |
1 | f.resize((3,8)) |
1 | print np.arange(12).reshape((3,4)) |
1 | print np.arange(12).reshape((3,4)).flatten() |
1 | g = np.arange(12) |
使用.astype改变Array数据类型,并不改变原数组的数据类型。
1 | type(g) |
1 | h = np.arange(24).reshape((2,3,4)) |
1 | h[:,1,-3] |
1 | h / h.mean() |
| 函数 | 描述 |
|---|---|
| np.abs(x) np.fabs(x) | 计算元素的绝对值 |
| np.sqrt(x) | 计算元素的平方根 |
| np.square(x) | 计算元素的平方 |
| np.log(x) np.log10(x) np.log2(x) | 计算元素的自然对数、10为底、2为底对数 |
| np.ceil(x) np.floor(x) | 计算元素的ceiliing floor值 |
| np.rint(x) | 计算元素的四舍五入值 |
| np.modf(x) | 计算元素的小数和整数部分以两个独立的数组形式返回 |
| np.cos/cosh/sin/sinh/tan/tanh(x) | 计算三角函数 |
| np.exp(x) | 计算元素的指数值 |
| np.sign(x) | 计算元素的符号值,1(+),0(0),-1(-) |
| 函数 | 描述 |
|---|---|
| + - * / ** | 加、减、乘、除、幂 |
| np.maximum(x,y) np.fmax() | 取最大值 |
| np.minimum(x,y) np.fmin() | 取最小值 |
| np.mod(x,y) | 模运算 |
| np.copysign(x,y) | 将数组y中各元素的符号赋值给数组x对应的元素 |
| > < >= <= == != | 产生布尔型数组 |
1 | h > (h/h.mean()) |
*** CSV只能有效存储一维和二维数组 ***
np.savetxt(frame, array, fmt='%.18e', delimiter=None)
.gz或.bz2的压缩文件。1 | np.savetxt('h.csv', h.reshape((3,8)), fmt="%d", delimiter=',') |
1 | cat h.csv |
np.loadtxt(frame, dtype=np.float, delimiter=None, unpack=False)
.gz或.bz2的压缩文件。1 | np.loadtxt('h.csv', delimiter=',') |
ndarray.tofile(frame, sep='', format='%s')
1 | h.tofile('h.dat', sep=',', format='%d') |
1 | cat h.dat |
np.fromfile(frame, dtype=np.float, count=-1, sep='')
1 | h.tofile('h.dat', sep=',', format='%d') |
使用fromfile读取文件,需要知道数组的shape
np.save(frame, array) or np.savez(frame, array)
.npy为扩展名,压缩扩展名为.npz1 | np.save('h.npy',h) |
1 | cat h.npy |
np.load(frame)
.npy为扩展名,压缩扩展名为.npz1 | np.load('h.npy') |
import numpy.random.* or np.random.rand()、np.random.randn()、np.random.randint() …
| 函数 | 描述 |
|---|---|
| rand(d0,d1…,dn) | 根据d0-dn创建随机数数组,浮点数,[0,1),均匀分布 |
| randn(d0,d1…,dn) | 根据d0-dn创建随机数数组,标准正态分布 |
| randint(low[,high,shape]) | 根据shape创建随机整数或整数数组,范围是[low,high) |
| seed(s) | 随机数种子,s是给定的种子值 |
1 | np.random.rand(2,3,4) |
| 函数 | 描述 |
|---|---|
| shuffle(a) | 对数组a按照最外维度进行随机排列,数组a改变 |
| permutation(a) | 对数组a按照最外维度进行随机排列,数组a不改变,生成新数组 |
| choice(a[,size,replace,p]) | 从一维数组中以概率p抽取元素,形成size形状新数组,replace表示是否重复抽取(默认True) |
1 | i = h.reshape((3,8)) |
| 函数 | 描述 |
|---|---|
| uniform(low,high,size) | 产生均匀分布的数组,low起始值,hight结束值,size形状 |
| normal(loc,scale,size) | 产生正态分布的数组,loc均值,scale标准差,size形状 |
| poisson(lam,size) | 产生泊松分布的数组,lam随机事件发生率,size形状 |
1 | np.random.uniform(0,10,(3,4)) |
NumPy直接提供库一级别的统计函数import numpy.* or np.std()、np.var()…
| 函数 | 描述 |
|---|---|
| sum(a, axis=None) | 对数组a求和,默认所有元素,axis指定维度 |
| mean((a, axis=None)a | 对数组a求平均值,默认所有元素,axis指定维度 |
| average(a, axis=None, weights=None) | 对数组a求加权平均值,默认所有元素,axis指定维度 |
| std(a, axis=None) | 对数组a求标准差,默认所有元素,axis指定维度 |
| var(a, axis=None) | 对数组a求方差,默认所有元素,axis指定维度 |
1 | print h |
| 函数 | 描述 |
|---|---|
| min(a) max(a) | 数组a中的最小值、最大值 |
| argmin(a) argmax(a) | 数组a中最小值、最大值降到一维后的下标索引 |
| unravel_index(index,shape) | 根据shape将一维下标索引index转换成多维下标索引 |
| ptp(a) | 数组a中最大值与最小值的差 |
| median(a) | 数组a中元素的中位数(中值) |
1 | print h |
连续值之间的变化率,即斜率。若有a,b,c三个值,b存在两侧值,b的梯度=(c-a)/2;若有a,b两个值,b只有一侧值,b或a的梯度=(b-a)/1
np.gradient(a)计算数组a中的梯度,若a为多维数组,返回每个维度梯度
1 | np.gradient(h) |
*** 梯度计算用于发现声音或图像数据的边缘,当梯度发生很大变化时,此处即为边缘 ***
在Hbase中,只有一个单一的按照字典序排序的rowKey索引,当使用rowKey来进行数据查询的时候速度较快,但是如果不使用rowKey来查询的话就会使用filter来对全表进行扫描,很大程度上降低了检索性能。而Phoenix提供了二级索引技术来应对这种使用rowKey之外的条件进行检索的场景。
Global indexing适用于多读少写的业务场景。使用Global indexing的话在写数据的时候会消耗大量开销,因为所有对数据表的更新操作(DELETE, UPSERT VALUES and UPSERT SELECT),会引起索引表的更新,而索引表是分布在不同的数据节点上的,跨节点的数据传输带来了较大的性能消耗。在读数据的时候Phoenix会选择索引表来降低查询消耗的时间。*** 在默认情况下如果想查询的字段不是索引字段的话索引表不会被使用,也就是说不会带来查询速度的提升。 ***
HBase集群的每个regionserver节点的hbase-site.xml中加入配置,并重启HBase集群
1 | <property> |
注: phoenix有两种链接方式JDBC和phoenix-client,phoenix-client可以正常创建索引;zeppelin使用jdbc连接不能正常创建索引,提示如下错误。
1 | java.sql.SQLException: ERROR 1029 (42Y88): Mutable secondary indexes must have the hbase.regionserver.wal.codec property set to org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec in the hbase-sites.xml of every region server. tableName=CMP_IDX |
在开始创建索引以前先创建一个表,并向其中填充测试数据(此处填充的数据仅用于功能测试)
1 | 0: jdbc:phoenix:> create table usertable (id varchar primary key,firstname varchar, lastname varchar); |
1 | base(main):019:0> scan 'USERTABLE' |
1 | 0: jdbc:phoenix:> create index idx_name on usertable (lastname) include(firstname); |
1 | hbase(main):020:0> scan 'IDX_NAME' |
正常的select … where … 是不会用到索引表的,要想用到索引表,必须查询出的字段也是索引字段。(此处的结论需要在后续的性能测试中进行验证)
1 | 0: jdbc:phoenix:> select firstname from usertable where lastname = 'phoenix'; |
Todo…
Todo…
Todo…
一个磁盘可以划分成多个分区,每个分区必须先用格式化工具(例如某种mkfs命令)格式化成某种格式的文件系统,然后才能存储文件,格式化的过程会在磁盘上写一些管理存储布局的信息。
文件系统中存储的最小单位是块(Block),一个块究竟多大是在格式化时确定的,例如mke2fs的-b选项可以设定块大小为1024、2048或4096字节。而上图中启动块(Boot Block)的大小是确定的,就是1KB,启动块是由PC标准规定的,用来存储磁盘分区信息和启动信息,任何文件系统都不能使用启动块。启动块之后才是ext2文件系统的开始,ext2文件系统将整个分区划成若干个同样大小的块组(Block Group)
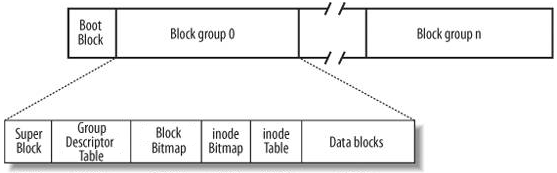
做一个EXT2的文件系统,然后将其挂载,看看其文件格式。
1 | dd if=/dev/zero of=./img.1m count=256 bs=4K |
使用od查看img.1m镜像文件
1 | od -tx1 -Ax ./img.1m |
描述整个分区的文件系统信息,例如块大小、文件系统版本号、上次mount的时间等等。超级块在每个块组的开头都有一份拷贝。
1 | struct ext2_super_block { |

从000000开始的1KB是启动块,由于这不是一个真正的磁盘分区,启动块的内容全部为零。从000400到0007ff的1KB是超级块,可以对照着dumpe2fs分析。
1 | dumpe2fs ./img.1m 1 |
块大小是1024字节,1MB的分区共有1024个块,第0个块是启动块,启动块之后才算ext2文件系统的开始,因此Group 0占据第1个到第1023个块,共1023个块。块位图占一个块,共有1024×8=8192个bit,足够表示这1023个块了,因此只要一个块组就够了。默认是每8KB分配一个inode,因此1MB的分区对应128个inode,这些数据都和dumpe2fs的输出吻合。
由很多块组描述符组成,整个分区分成多少个块组就对应有多少个块组描述符。每个块组描述符(Group Descriptor)存储一个块组的描述信息,例如在这个块组中从哪里开始是inode表,从哪里开始是数据块,空闲的inode和数据块还有多少个等等。和超级块类似,块组描述符表在每个块组的开头也都有一份拷贝,这些信息是非常重要的,一旦超级块意外损坏就会丢失整个分区的数据,一旦块组描述符意外损坏就会丢失整个块组的数据,因此它们都有多份拷贝。通常内核只用到第0个块组中的拷贝,当执行e2fsck检查文件系统一致性时,第0个块组中的超级块和块组描述符表就会拷贝到其它块组,这样当第0个块组的开头意外损坏时就可以用其它拷贝来恢复,从而减少损失。
1 | /* |

从000800开始是块组描述符表,这个文件系统较小,只有一个块组描述符,对照着dumpe2fs的输出信息分析
1 | dumpe2fs ./img.1m 1 |
整个文件系统是1MB,每个块是1KB,应该有1024个块,除去启动块还有1023个块,分别编号为1-1023,它们全都属于Group 0。其中,Block 1是超级块,接下来的块组描述符指出,块位图是Block 6,因此中间的Block 2-5是块组描述符表,其中Block 3-5保留未用。块组描述符还指出,inode位图是Block 7,inode表是从Block 8开始的,那么inode表到哪个块结束呢?由于超级块中指出每个块组有128个inode,每个inode的大小是128字节,因此共占16个块,inode表的范围是Block 8-23。从Block 24开始就是数据块了。块组描述符中指出,空闲的数据块有986个,由于文件系统是新创建的,空闲块是连续的Block 38-1023,用掉了前面的Block 24-37
一个块组中的块是这样利用的:数据块(Data Block)存储所有文件的数据,比如某个分区的块大小是1024字节,某个文件是2049字节,那么就需要三个数据块来存,即使第三个块只存了一个字节也需要占用一个整块;超级块、块组描述符表、块位图、inode位图、inode表这几部分存储该块组的描述信息。那么如何知道哪些块已经用来存储文件数据或其它描述信息,哪些块仍然空闲可用呢?块位图就是用来描述整个块组中哪些块已用哪些块空闲的,它本身占一个块,其中的每个bit代表本块组中的一个块,这个bit为1表示该块已用,这个bit为0表示该块空闲可用。
为什么用df命令统计整个磁盘的已用空间非常快呢?因为只需要查看每个块组的块位图即可,而不需要搜遍整个分区。相反,用du命令查看一个较大目录的已用空间就非常慢,因为不可避免地要搜遍整个目录的所有文件。
与此相联系的另一个问题是:在格式化一个分区时究竟会划出多少个块组呢?主要的限制在于块位图本身必须只占一个块。用mke2fs格式化时默认块大小是1024字节,可以用-b参数指定块大小,现在设块大小指定为b字节,那么一个块可以有8b个bit,这样大小的一个块位图就可以表示8b个块的占用情况,因此一个块组最多可以有8b个块,如果整个分区有s个块,那么就可以有s/(8b)个块组。格式化时可以用-g参数指定一个块组有多少个块,但是通常不需要手动指定,mke2fs工具会计算出最优的数值。
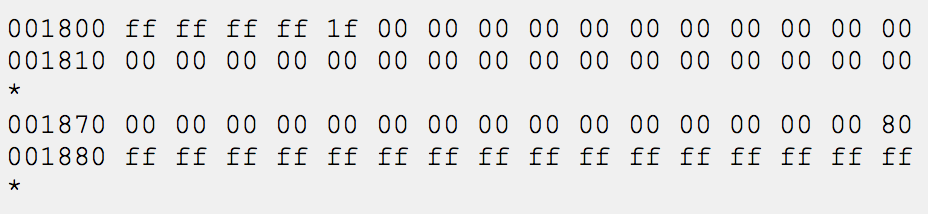
从块位图中可以看出,前37位(前4个字节加最后一个字节的低5位)都是1,,就表示Block 1-37已用。在块位图中,Block 38-1023对应的位都是0(一直到001870那一行最后一个字节的低7位),接下来的位已经超出了文件系统的空间,不管是0还是1都没有意义。可见,块位图每个字节中的位应该按从低位到高位的顺序来看。以后随着文件系统的使用和添加删除文件,块位图中的1就变得不连续了。
和块位图类似,本身占一个块,其中每个bit表示一个inode是否空闲可用。

块组描述符指出,空闲的inode有117个,由于文件系统是新创建的,空闲的inode也是连续的,inode编号从1到128,空闲的inode编号从12到128。从inode位图可以看出,前11位都是1,表示前11个inode已用。以后随着文件系统的使用和添加删除文件,inode位图中的1就变得不连续了。001c00这一行的128位就表示了所有inode,因此下面的行不管是0还是1都没有意义。已用的11个inode中,前10个inode是被ext2文件系统保留的,其中第2个inode是根目录,第11个inode是lost+found目录,块组描述符也指出该组有两个目录,就是根目录和lost+found。
一个文件除了数据需要存储之外,一些描述信息也需要存储,例如文件类型(常规、目录、符号链接等),权限,文件大小,创建/修改/访问时间等,也就是ls -l命令看到的那些信息,这些信息存在inode中而不是数据块中。每个文件都有一个inode,一个块组中的所有inode组成了inode表。
inode表占多少个块在格式化时就要决定并写入块组描述符中,mke2fs格式化工具的默认策略是一个块组有多少个8KB就分配多少个inode。由于数据块占了整个块组的绝大部分,也可以近似认为数据块有多少个8KB就分配多少个inode,换句话说,如果平均每个文件的大小是8KB,当分区存满的时候inode表会得到比较充分的利用,数据块也不浪费。如果这个分区存的都是很大的文件(比如电影),则数据块用完的时候inode会有一些浪费,如果这个分区存的都是很小的文件(比如源代码),则有可能数据块还没用完inode就已经用完了,数据块可能有很大的浪费。如果用户在格式化时能够对这个分区以后要存储的文件大小做一个预测,也可以用mke2fs的-i参数手动指定每多少个字节分配一个inode。
1 | /* |
根目录inode信息: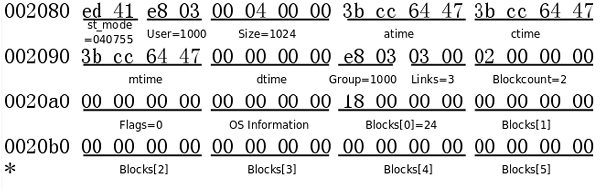
st_mode以八进制表示,包含了文件类型和文件权限,最高位的4表示文件类型为目录(各种文件类型的编码详见stat(2)),低位的755表示权限。Size是1024,说明根目录现在只有一个数据块。Links为3表示根目录有三个硬链接,分别是根目录下的.和..,以及lost+found子目录下的..。注意,虽然我们通常用/表示根目录,但是并没有名为/的硬链接,事实上,/是路径分隔符,不能在文件名中出现。这里的Blockcount是以512字节为一个块来数的,并非格式化文件系统时所指定的块大小,磁盘的最小读写单位称为扇区(Sector),通常是512字节,所以Blockcount是磁盘的物理块数量,而非分区的逻辑块数量。根目录数据块的位置由上图中的Blocks[0]指出,也就是第24个块,它在文件系统中的位置是24×0x400=0x6000
探索文件系统还有一个很有用的工具debugfs,它提供一个命令行界面,可以对文件系统做各种操作,例如查看信息、恢复数据、修正文件系统中的错误。使用debugfs ./img.1m打开文件系统,使用stat /命令查看根目录inode信息
1 | Inode: 2 Type: directory Mode: 0755 Flags: 0x0 |
通过__le32 i_block[EXT2_N_BLOCKS]来完成数据块的寻址。
1 | /* |
EXT2_NDIR_BLOCKSi_block前12项属于直接寻址,直接存储数据块的”block id”。所以总共可记录 12 笔记录,总额大小为12*1k=12kEXT2_IND_BLOCKi_block第13项为一级间接寻址,每笔 block 号码的记录会花去 4bytes,因此 1K 的大小能够记录 256 笔记录,因此一个间接可以记录的文件大小为(1k/4)*1K=256kEXT2_DIND_BLOCKi_block第14项为二级间接寻址,第一层 block 会指定 256 个第二层,每个第二层可以指定 256 个号码,因此总额大小为2562561kEXT2_TIND_BLOCKi_block第15项为三级间接寻址,第一层 block 会指定 256 个第二层,每个第二层可以指定 256 个第三层,每个第三层可以指定 256 个号码,因此总额大小为256256256*1k*** 总容量为直接寻址+一级间接+二级间接+三级间接=16.06GB ***
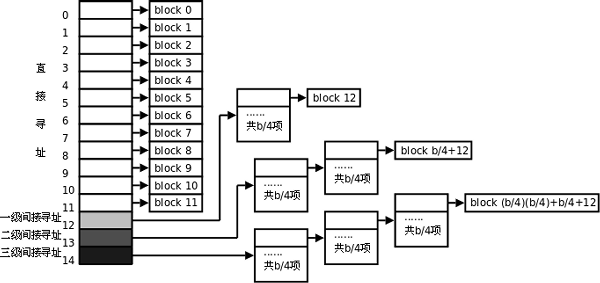
根目录的数据结构
1 | struct ext2_dir_entry_2 { |
根目录的数据块
根据上文中根目录inode信息找到根目录数据块006000地址,目录的数据块由许多不定长的记录组成,每条记录描述该目录下的一个文件,在上图中用框表示。第一条记录描述inode号为2的文件,也就是根目录本身,该记录的总长度为12字节,其中文件名的长度为1字节,文件类型为2(见下表,注意此处的文件类型编码和st_mode不一致),文件名是.。第二条记录也是描述inode号为2的文件(根目录),该记录总长度为12字节,其中文件名的长度为2字节,文件类型为2,文件名字符串是..。第三条记录一直延续到该数据块的末尾,描述inode号为11的文件(lost+found目录),该记录的总长度为1000字节(和前面两条记录加起来是1024字节),文件类型为2,文件名字符串是lost+found,后面全是0字节。如果要在根目录下创建新的文件,可以把第三条记录截短,在原来的0字节处创建新的记录。如果该目录下的文件名太多,一个数据块不够用,则会分配新的数据块,块编号会填充到inode的Blocks[1]字段。
| 编码 | 文件类型(file type) |
|---|---|
| 0 | Unknown |
| 1 | Regular File |
| 2 | Directory |
| 3 | Character device |
| 4 | Block device |
| 5 | Named pipe |
| 6 | Socket |
| 7 | Symbolic link |
1 | try: |
1 | try: |
1 | raise [Exception [, args [, traceback]]] |
Exception是异常的类型(例如,NameError)参数是一个异常参数值。该参数是可选的,如果不提供,异常的参数是”None”。最后一个参数是可选的(在实践中很少使用),如果存在,是跟踪异常对象。
| 异常名称 | 描述 |
|---|---|
| BaseException | 所有异常的基类 |
| SystemExit | 解释器请求退出 |
| KeyboardInterrupt | 用户中断执行(通常是输入^C) |
| Exception | 常规错误的基类 |
| StopIteration | 迭代器没有更多的值 |
| GeneratorExit | 生成器(generator)发生异常来通知退出 |
| StandardError | 所有的内建标准异常的基类 |
| ArithmeticError | 所有数值计算错误的基类 |
| FloatingPointError | 浮点计算错误 |
| OverflowError | 数值运算超出最大限制 |
| ZeroDivisionError | 除(或取模)零 (所有数据类型) |
| AssertionError | 断言语句失败 |
| AttributeError | 对象没有这个属性 |
| EOFError | 没有内建输入,到达EOF 标记 |
| EnvironmentError | 操作系统错误的基类 |
| IOError | 输入/输出操作失败 |
| OSError | 操作系统错误 |
| WindowsError | 系统调用失败 |
| ImportError | 导入模块/对象失败 |
| LookupError | 无效数据查询的基类 |
| IndexError | 序列中没有此索引(index) |
| KeyError | 映射中没有这个键 |
| MemoryError | 内存溢出错误(对于Python 解释器不是致命的) |
| NameError | 未声明/初始化对象 (没有属性) |
| UnboundLocalError | 访问未初始化的本地变量 |
| ReferenceError | 弱引用(Weak reference)试图访问已经垃圾回收了的对象 |
| RuntimeError | 一般的运行时错误 |
| NotImplementedError | 尚未实现的方法 |
| SyntaxError | Python 语法错误 |
| IndentationError | 缩进错误 |
| TabError | Tab 和空格混用 |
| SystemError | 一般的解释器系统错误 |
| TypeError | 对类型无效的操作 |
| ValueError | 传入无效的参数 |
| UnicodeError | Unicode 相关的错误 |
| UnicodeDecodeError | Unicode 解码时的错误 |
| UnicodeEncodeError | Unicode 编码时错误 |
| UnicodeTranslateError | Unicode 转换时错误 |
| Warning | 警告的基类 |
| DeprecationWarning | 关于被弃用的特征的警告 |
| FutureWarning | 关于构造将来语义会有改变的警告 |
| OverflowWarning | 旧的关于自动提升为长整型(long)的警告 |
| PendingDeprecationWarning | 关于特性将会被废弃的警告 |
| RuntimeWarning | 可疑的运行时行为(runtime behavior)的警告 |
| SyntaxWarning | 可疑的语法的警告 |
| UserWarning | 用户代码生成的警告 |
python不能直接访问hbase,必须通过thrift插件才能访问hbase,下面是对hbase和thriftpython插件的安装
1 | pip install thrift |
hbase_client.py
1 | #!/usr/bin/python |
test.py
1 | import hbase_client as hc |
计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节。比如两个字节可以表示的最大整数是65535,4个字节可以表示的最大整数是4294967295。
规定了128个字符的编码(准确地说ASCII码是一个编码字符集),比如空格“SPACE”是32(二进制00100000),大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的1位统一规定为0。后128个称为扩展ASCII码,目前许多基于x86的系统都支持使用扩展ASCII码。256个ASCII码中的后128个扩展码可定制用来表示特殊字符和非英语字符,GB2312就是利用这后面的128个扩展字符来表示汉字,[161,254]共94个字符来组成双字节来表示简体汉字字符表。
光是英语字符ASCII编码字符集是够了,但是如果算上世界上其他的语言的字符,ASCII码显然不够了,于是Unicode编码字符集应运而生。Unicode用数字0-0x10FFFF来映射这些字符,最多可以容纳1114112个字符,或者说有1114112个码位。码位就是可以分配给字符的数字。UTF-8、UTF-16、UTF-32都是将所有Unicode用到的数字转换为程序数据的编码方案。全世界的字符加起来也用不了所有的码位,Unicode 5.0版本中,才用了238605个码位。
新问题的出现:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。因此,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间。ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。Unicode是字符集,UTF-8、UTF-16等是编码格式,定义“字符对应的数字”如何在以二进制的方式存储。
规定: 一个小于127的字符的意义与原来相同, 但两个大于127的字符连在一起时, 就表示一个汉字, 前面的一个字节(他称之为高字节)从0xA1用到 0xF7, 后面一个字节(低字节)从0xA1到0xFE, 这样我们就可以组合出大约7000多个简体汉字了. 在这些编码里, 我们还把数学符号,罗马希腊的 字母,日文的假名们都编进去了, 连在 ASCII 里本来就有的数字,标点,字母都统统重新编了两个字节长的编码, 这就是常说的”全角”字符, 而原来在127号以下的那些就叫”半角”字符了。
GBK 包括了 GB2312 的所有内容, 同时又增加了近20000个新的汉字(包括繁体字)和符号。
unicode兼容ascii,GBK兼容GB2312,转换也就是unicode与GBK之间的事情了。字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码。
1 | #encoding=utf8 |