function upgrade(address newImplementation) external { require(msg.sender == admin, "Only admin can upgrade"); implementation = newImplementation; }
function getData(uint256 _num) public pure returns (bytes memory) { return abi.encodeWithSignature("setNumber(uint256)", _num); } }
// Logic contract (v1) contract LogicV1 { uint256 public number; address public implementation; address public admin; uint256 public privateNum; function setNumber(uint256 _number) public { number = _number; privateNum = _number; } }
// Logic contract (v2) contract LogicV2 { uint256 public number; address public implementation; address public admin; uint256 public privateNum; function setNumber(uint256 _number) public { number = _number * 2; // Updated logic privateNum = _number * 2; } }
// SPDX-License-Identifier: MIT pragma solidity ^0.8.0;
interface ILOGIC { function setNumber(uint256 _number) external ; }
contract Router { mapping(string => address) public modules; address public admin; constructor() { admin = msg.sender; } function updateModule(string memory moduleName, address moduleAddress) external { require(msg.sender == admin, "Only admin can update"); modules[moduleName] = moduleAddress; } function setNumber(string memory moduleName, uint256 _num) external { address module = modules[moduleName]; require(module != address(0), "Module not found"); ILOGIC(module).setNumber(_num); } }
// Logic contract (v1) contract LogicV1 is ILOGIC { uint256 public number; uint256 public privateNum; function setNumber(uint256 _number) public { number = _number; privateNum = _number; } }
// Logic contract (v2) contract LogicV2 is ILOGIC { uint256 public number; uint256 public privateNum; function setNumber(uint256 _number) public { number = _number * 2; // Updated logic privateNum = _number * 2; } }
// SPDX-License-Identifier: MIT // Compatible with OpenZeppelin Contracts ^5.0.0 pragma solidity ^0.8.22;
import {AccessManaged} from "@openzeppelin/contracts/access/manager/AccessManaged.sol"; import {ERC20} from "@openzeppelin/contracts/token/ERC20/ERC20.sol"; import {ERC20Pausable} from "@openzeppelin/contracts/token/ERC20/extensions/ERC20Pausable.sol"; import {ERC20Permit} from "@openzeppelin/contracts/token/ERC20/extensions/ERC20Permit.sol";
// SPDX-License-Identifier: MIT // OpenZeppelin Contracts (last updated v5.1.0) (token/ERC20/ERC20.sol)
pragma solidity ^0.8.20;
import {IERC20} from "./IERC20.sol"; import {IERC20Metadata} from "./extensions/IERC20Metadata.sol"; import {Context} from "../../utils/Context.sol"; import {IERC20Errors} from "../../interfaces/draft-IERC6093.sol";
function transfer(address to, uint256 value) public virtual returns (bool) { address owner = _msgSender(); _transfer(owner, to, value); return true; }
function transferFrom(address from, address to, uint256 value) public virtual returns (bool) { address spender = _msgSender(); _spendAllowance(from, spender, value); _transfer(from, to, value); return true; }
function _transfer(address from, address to, uint256 value) internal { if (from == address(0)) { revert ERC20InvalidSender(address(0)); } if (to == address(0)) { revert ERC20InvalidReceiver(address(0)); } _update(from, to, value); }
function _update(address from, address to, uint256 value) internal virtual { if (from == address(0)) { // Overflow check required: The rest of the code assumes that totalSupply never overflows _totalSupply += value; } else { uint256 fromBalance = _balances[from]; if (fromBalance < value) { revert ERC20InsufficientBalance(from, fromBalance, value); } unchecked { // Overflow not possible: value <= fromBalance <= totalSupply. _balances[from] = fromBalance - value; } }
if (to == address(0)) { unchecked { // Overflow not possible: value <= totalSupply or value <= fromBalance <= totalSupply. _totalSupply -= value; } } else { unchecked { // Overflow not possible: balance + value is at most totalSupply, which we know fits into a uint256. _balances[to] += value; } }
// SPDX-License-Identifier: MIT // OpenZeppelin Contracts (last updated v5.1.0) (token/ERC20/extensions/ERC20Pausable.sol)
pragma solidity ^0.8.20;
import {ERC20} from "../ERC20.sol"; import {Pausable} from "../../../utils/Pausable.sol";
abstract contract ERC20Pausable is ERC20, Pausable { /** * @dev See {ERC20-_update}. * * Requirements: * * - the contract must not be paused. */ function _update(address from, address to, uint256 value) internal virtual override whenNotPaused { super._update(from, to, value); } }
// SPDX-License-Identifier: MIT // OpenZeppelin Contracts (last updated v5.1.0) (access/manager/AccessManaged.sol)
pragma solidity ^0.8.20;
import {IAuthority} from "./IAuthority.sol"; import {AuthorityUtils} from "./AuthorityUtils.sol"; import {IAccessManager} from "./IAccessManager.sol"; import {IAccessManaged} from "./IAccessManaged.sol"; import {Context} from "../../utils/Context.sol";
abstract contract AccessManaged is Context, IAccessManaged { address private _authority;
// SPDX-License-Identifier: MIT // OpenZeppelin Contracts (last updated v5.1.0) (token/ERC20/extensions/ERC20Permit.sol)
pragma solidity ^0.8.20;
import {IERC20Permit} from "./IERC20Permit.sol"; import {ERC20} from "../ERC20.sol"; import {ECDSA} from "../../../utils/cryptography/ECDSA.sol"; import {EIP712} from "../../../utils/cryptography/EIP712.sol"; import {Nonces} from "../../../utils/Nonces.sol";
/** @dev Implementation of the ERC-20 Permit extension allowing approvals to be made via signatures, as defined in * https://eips.ethereum.org/EIPS/eip-2612[ERC-2612]. * * Adds the {permit} method, which can be used to change an account's ERC-20 allowance (see {IERC20-allowance}) by * presenting a message signed by the account. By not relying on `{IERC20-approve}`, the token holder account doesn't * need to send a transaction, and thus is not required to hold Ether at all. */ abstract contract ERC20Permit is ERC20, IERC20Permit, EIP712, Nonces { bytes32 private constant PERMIT_TYPEHASH = keccak256("Permit(address owner,address spender,uint256 value,uint256 nonce,uint256 deadline)"); /** * @dev Permit deadline has expired. */ error ERC2612ExpiredSignature(uint256 deadline); /** * @dev Mismatched signature. */ error ERC2612InvalidSigner(address signer, address owner); /** * @dev Initializes the {EIP712} domain separator using the `name` parameter, and setting `version` to `"1"`. * * It's a good idea to use the same `name` that is defined as the ERC-20 token name. */ constructor(string memory name) EIP712(name, "1") {} /** * @inheritdoc IERC20Permit */ function permit( address owner, address spender, uint256 value, uint256 deadline, uint8 v, bytes32 r, bytes32 s ) public virtual { if (block.timestamp > deadline) { revert ERC2612ExpiredSignature(deadline); } bytes32 structHash = keccak256(abi.encode(PERMIT_TYPEHASH, owner, spender, value, _useNonce(owner), deadline)); bytes32 hash = _hashTypedDataV4(structHash); address signer = ECDSA.recover(hash, v, r, s); if (signer != owner) { revert ERC2612InvalidSigner(signer, owner); } _approve(owner, spender, value); } /** * @inheritdoc IERC20Permit */ function nonces(address owner) public view virtual override(IERC20Permit, Nonces) returns (uint256) { return super.nonces(owner); } /** * @inheritdoc IERC20Permit */ // solhint-disable-next-line func-name-mixedcase function DOMAIN_SEPARATOR() external view virtual returns (bytes32) { return _domainSeparatorV4(); } }
// SPDX-License-Identifier: MIT // Compatible with OpenZeppelin Contracts ^5.0.0 pragma solidity ^0.8.22;
import {AccessManaged} from "@openzeppelin/contracts/access/manager/AccessManaged.sol"; import {ERC20} from "@openzeppelin/contracts/token/ERC20/ERC20.sol"; import {ERC20Pausable} from "@openzeppelin/contracts/token/ERC20/extensions/ERC20Pausable.sol"; import {ERC20Permit} from "@openzeppelin/contracts/token/ERC20/extensions/ERC20Permit.sol";
cd /usr/src/linux-source-5.15.0/debian tar -jxvf linux-source-5.15.0.tar.bz2
Copy config文件
1 2 3
cd linux-source-5.15.0 cp -v /boot/config-$(uname -r) .config make oldconfig && make prepare
编译Samples
1
make -C samples/bpf
若遇到如下错误
1 2 3 4 5 6 7 8
...... CC /usr/src/linux-source-5.15.0/samples/bpf/bpftool/prog.o LINK /usr/src/linux-source-5.15.0/samples/bpf/bpftool/bpftool /usr/src/linux-source-5.15.0/samples/bpf/Makefile:369: *** Cannot find a vmlinux for VMLINUX_BTF at any of " /usr/src/linux-source-5.15.0/vmlinux", build the kernel or set VMLINUX_BTF or VMLINUX_H variable. Stop. make[1]: *** [Makefile:1911: /usr/src/linux-source-5.15.0/samples/bpf] Error 2 make[1]: Leaving directory '/usr/src/linux-source-5.15.0' make: *** [Makefile:275: all] Error 2 make: Leaving directory '/usr/src/linux-source-5.15.0/samples/bpf'
说明需要 vmlinux,可以指定vmlinux再进行编译
1
make VMLINUX_BTF=/sys/kernel/btf/vmlinux -C samples/bpf
or
1
make VMLINUX_BTF=/sys/kernel/btf/vmlinux M=samples/bpf
bob@ubu1:~$ lsb_release -a No LSB modules are available. Distributor ID: Ubuntu Description: Ubuntu 20.04.5 LTS Release: 20.04 Codename: focal bob@ubu1:~$ uname -a Linux ubu1 5.4.0-139-generic #156-Ubuntu SMP Sat Jan 21 13:46:46 UTC 2023 aarch64 aarch64 aarch64 GNU/Linux
1 2 3 4 5 6 7 8
bob@ubu2:~$ lsb_release -a No LSB modules are available. Distributor ID: Ubuntu Description: Ubuntu 20.04.5 LTS Release: 20.04 Codename: focal bob@ubu2:~$ uname -a Linux ubu2 5.4.0-139-generic #156-Ubuntu SMP Sat Jan 21 13:46:46 UTC 2023 aarch64 aarch64 aarch64 GNU/Linux
bob@ubu1:~$ sudo apt-cache show drbd-utils Package: drbd-utils Architecture: arm64 Version: 9.11.0-1build1 Priority: extra Section: admin Origin: Ubuntu Maintainer: Ubuntu Developers <ubuntu-devel-discuss@lists.ubuntu.com> Original-Maintainer: Debian DRBD Maintainers <debian-ha-maintainers@lists.alioth.debian.org> Bugs: https://bugs.launchpad.net/ubuntu/+filebug Installed-Size: 2062 Depends: lsb-base (>= 3.0-6), libc6 (>= 2.28), libgcc-s1 (>= 3.0), libstdc++6 (>= 5.2), init-system-helpers (>= 1.51) Recommends: heirloom-mailx | mailx Suggests: heartbeat Breaks: drbd8-utils (<< 2:8.9.0) Replaces: drbd8-utils (<< 2:8.9.0) Filename: pool/main/d/drbd-utils/drbd-utils_9.11.0-1build1_arm64.deb Size: 654128 MD5sum: 45a8962e941c9a87c7de423de34f616b SHA1: 3734ee6c0611348c5b8c080feb713c05f9d84c4c SHA256: ae63aa90d145faab00551f151c10588bafebe2673e64b137c980cce7c299bccf Homepage: https://www.drbd.org/ Description-en: RAID 1 over TCP/IP for Linux (user utilities) Drbd is a block device which is designed to build high availability clusters by providing a virtual shared device which keeps disks in nodes synchronised using TCP/IP. This simulates RAID 1 but avoiding the use of uncommon hardware (shared SCSI buses or Fibre Channel). It is currently limited to fail-over HA clusters. . This package contains the programs that will control the drbd kernel module provided in the Linux kernel. Description-md5: 7da3dade742b03d1a9c08b339123f93b
bob@ubu1:~$ apt install drbd-utils
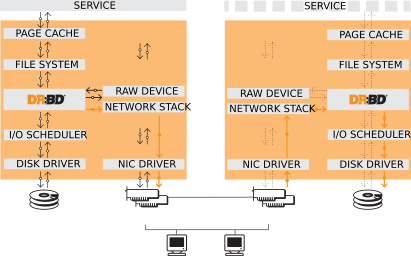
两个节点ubu1和ubu2都需要安装这个drbd-utils包
常规用法
配置
配置/etc/drbd.d/global_common.conf
1 2 3 4 5 6 7 8 9
global { usage-count yes; }
common { net { protocol C; } }
DRBD系统向虚拟块的镜像中写入数据时,支持三种协议
protocol A 数据一旦写入磁盘并发送到网络中就认为完成了写入操作
protocol B 收到接收确认就认为完成了写入操作
protocol C 收到写入确认就认为完成了写入操作
基于安全考虑我们一般选择protocol C
配置DRBD资源/etc/drbd.d/r0.res
1 2 3 4 5 6 7 8 9 10 11 12 13 14
resource r0 { on ubu1 { device /dev/drbd1; disk /dev/sda; address 192.168.64.2:7789; meta-disk internal; } on ubu2 { device /dev/drbd1; disk /dev/sda; address 192.168.64.4:7789; meta-disk internal; } }
Do you want to proceed? [need to type 'yes' to confirm] yes
initializing activity log initializing bitmap (672 KB) to all zero Writing meta data... New drbd meta data block successfully created. success bob@ubu1:~/drbd_res$ sudo drbdadm up r2 bob@ubu1:~/drbd_res$ sudo drbdadm primary --force r2 bob@ubu1:~/drbd_res$ cat /proc/drbd version: 8.4.11 (api:1/proto:86-101) srcversion: B438804C5AE8C84C95D0411
bob@ubu2:~$ sudo drbdadm create-md r2 initializing activity log initializing bitmap (704 KB) to all zero Writing meta data... New drbd meta data block successfully created. success
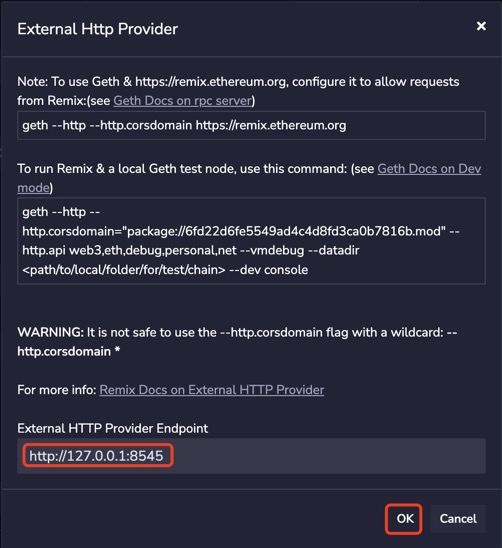
# geth --datadir ./eth-data --allow-insecure-unlock --http --http.addr 172.17.0.2 --http.api "admin,debug,web3,eth,txpool,personal,ethash,miner,net" --http.corsdomain "*" --dev init genesis.json INFO [11-07|16:04:14.139] Maximum peer count ETH=50 LES=0 total=50 INFO [11-07|16:04:14.151] Smartcard socket not found, disabling err="stat /run/pcscd/pcscd.comm: no such file or directory" INFO [11-07|16:04:14.179] Set global gas cap cap=50,000,000 INFO [11-07|16:04:14.190] Allocated cache and file handles database=/root/eth-data/geth/chaindata cache=16.00MiB handles=16 INFO [11-07|16:04:14.224] Opened ancient database database=/root/eth-data/geth/chaindata/ancient/chain readonly=false INFO [11-07|16:04:14.226] Writing custom genesis block INFO [11-07|16:04:14.230] Persisted trie from memory database nodes=0 size=0.00B time="347µs" gcnodes=0 gcsize=0.00B gctime=0s livenodes=1 livesize=0.00B INFO [11-07|16:04:14.238] Successfully wrote genesis state database=chaindata hash=a697c6..9bf39b INFO [11-07|16:04:14.238] Allocated cache and file handles database=/root/eth-data/geth/lightchaindata cache=16.00MiB handles=16 INFO [11-07|16:04:14.259] Opened ancient database database=/root/eth-data/geth/lightchaindata/ancient/chain readonly=false INFO [11-07|16:04:14.259] Writing custom genesis block INFO [11-07|16:04:14.261] Persisted trie from memory database nodes=0 size=0.00B time="21.917µs" gcnodes=0 gcsize=0.00B gctime=0s livenodes=1 livesize=0.00B INFO [11-07|16:04:14.262] Successfully wrote genesis state database=lightchaindata hash=a697c6..9bf39b
# geth --datadir ./eth-data --networkid 110 --allow-insecure-unlock --http --http.addr 172.17.0.2 --http.api "admin,debug,web3,eth,txpool,personal,ethash,miner,net" --http.corsdomain "*" --dev INFO [11-07|16:14:23.231] Starting Geth in ephemeral dev mode... WARN [11-07|16:14:23.234] You are running Geth in --dev mode. Please note the following:
1. This mode is only intended for fast, iterative development without assumptions on security or persistence. 2. The database is created in memory unless specified otherwise. Therefore, shutting down your computer or losing power will wipe your entire block data and chain state for your dev environment. 3. A random, pre-allocated developer account will be available and unlocked as eth.coinbase, which can be used for testing. The random dev account is temporary, stored on a ramdisk, and will be lost if your machine is restarted. 4. Mining is enabled by default. However, the client will only seal blocks if transactions are pending in the mempool. The miner's minimum accepted gas price is 1. 5. Networking is disabled; there is no listen-address, the maximum number of peers is set to 0, and discovery is disabled. INFO [11-07|16:14:23.251] Maximum peer count ETH=50 LES=0 total=50 INFO [11-07|16:14:23.261] Smartcard socket not found, disabling err="stat /run/pcscd/pcscd.comm: no such file or directory" INFO [11-07|16:14:23.291] Set global gas cap cap=50,000,000 INFO [11-07|16:14:23.649] Using developer account address=0xA9CB6DB62D6673ae5CD79D0d29796Dd9DF1d1A5e INFO [11-07|16:14:23.652] Allocated cache and file handles database=/root/eth-data/geth/chaindata cache=512.00MiB handles=524,288 readonly=true INFO [11-07|16:14:23.675] Opened ancient database database=/root/eth-data/geth/chaindata/ancient/chain readonly=true INFO [11-07|16:14:23.691] Allocated trie memory caches clean=154.00MiB dirty=256.00MiB INFO [11-07|16:14:23.691] Allocated cache and file handles database=/root/eth-data/geth/chaindata cache=512.00MiB handles=524,288 INFO [11-07|16:14:23.756] Opened ancient database database=/root/eth-data/geth/chaindata/ancient/chain readonly=false INFO [11-07|16:14:23.763] INFO [11-07|16:14:23.764] --------------------------------------------------------------------------------------------------------------------------------------------------------- INFO [11-07|16:14:23.764] Chain ID: 110 (unknown) INFO [11-07|16:14:23.764] Consensus: unknown INFO [11-07|16:14:23.764] INFO [11-07|16:14:23.765] Pre-Merge hard forks: INFO [11-07|16:14:23.765] - Homestead: 0 (https://github.com/ethereum/execution-specs/blob/master/network-upgrades/mainnet-upgrades/homestead.md) INFO [11-07|16:14:23.765] - Tangerine Whistle (EIP 150): 0 (https://github.com/ethereum/execution-specs/blob/master/network-upgrades/mainnet-upgrades/tangerine-whistle.md) INFO [11-07|16:14:23.765] - Spurious Dragon/1 (EIP 155): 0 (https://github.com/ethereum/execution-specs/blob/master/network-upgrades/mainnet-upgrades/spurious-dragon.md) INFO [11-07|16:14:23.765] - Spurious Dragon/2 (EIP 158): 0 (https://github.com/ethereum/execution-specs/blob/master/network-upgrades/mainnet-upgrades/spurious-dragon.md) INFO [11-07|16:14:23.765] - Byzantium: <nil> (https://github.com/ethereum/execution-specs/blob/master/network-upgrades/mainnet-upgrades/byzantium.md) INFO [11-07|16:14:23.765] - Constantinople: <nil> (https://github.com/ethereum/execution-specs/blob/master/network-upgrades/mainnet-upgrades/constantinople.md) INFO [11-07|16:14:23.765] - Petersburg: <nil> (https://github.com/ethereum/execution-specs/blob/master/network-upgrades/mainnet-upgrades/petersburg.md) INFO [11-07|16:14:23.766] - Istanbul: <nil> (https://github.com/ethereum/execution-specs/blob/master/network-upgrades/mainnet-upgrades/istanbul.md) INFO [11-07|16:14:23.766] - Berlin: <nil> (https://github.com/ethereum/execution-specs/blob/master/network-upgrades/mainnet-upgrades/berlin.md) INFO [11-07|16:14:23.766] - London: <nil> (https://github.com/ethereum/execution-specs/blob/master/network-upgrades/mainnet-upgrades/london.md) INFO [11-07|16:14:23.766] INFO [11-07|16:14:23.766] The Merge is not yet available for this network! INFO [11-07|16:14:23.766] - Hard-fork specification: https://github.com/ethereum/execution-specs/blob/master/network-upgrades/mainnet-upgrades/paris.md INFO [11-07|16:14:23.766] --------------------------------------------------------------------------------------------------------------------------------------------------------- INFO [11-07|16:14:23.766] INFO [11-07|16:14:23.768] Disk storage enabled for ethash caches dir=/root/eth-data/geth/ethash count=3 INFO [11-07|16:14:23.768] Disk storage enabled for ethash DAGs dir=/root/.ethash count=2 INFO [11-07|16:14:23.769] Initialising Ethereum protocol network=1337 dbversion=8 INFO [11-07|16:14:23.779] Loaded most recent local header number=0 hash=a697c6..9bf39b td=0 age=53y7mo1w INFO [11-07|16:14:23.780] Loaded most recent local full block number=0 hash=a697c6..9bf39b td=0 age=53y7mo1w INFO [11-07|16:14:23.780] Loaded most recent local fast block number=0 hash=a697c6..9bf39b td=0 age=53y7mo1w INFO [11-07|16:14:23.786] Loaded local transaction journal transactions=0 dropped=0 INFO [11-07|16:14:23.786] Regenerated local transaction journal transactions=0 accounts=0 INFO [11-07|16:14:23.791] Gasprice oracle is ignoring threshold set threshold=2 WARN [11-07|16:14:23.798] Engine API enabled protocol=eth WARN [11-07|16:14:23.798] Engine API started but chain not configured for merge yet INFO [11-07|16:14:23.802] Starting peer-to-peer node instance=Geth/v1.10.26-stable-e5eb32ac/linux-amd64/go1.18.5 WARN [11-07|16:14:23.802] P2P server will be useless, neither dialing nor listening INFO [11-07|16:14:23.843] New local node record seq=1,667,808,816,313 id=321fce2047223769 ip=127.0.0.1 udp=0 tcp=0 INFO [11-07|16:14:23.844] Started P2P networking self=enode://2d0246c1dd51623d6d8a8581095c033542366037b1e20ff815ad045af396de50df60f4aa9556148c2f4a89673bad5cab5c2ab22f3075d5bacba1b2fbebaf72e5@127.0.0.1:0 INFO [11-07|16:14:23.848] IPC endpoint opened url=/root/eth-data/geth.ipc INFO [11-07|16:14:23.852] Loaded JWT secret file path=/root/eth-data/geth/jwtsecret crc32=0xef39c4cb INFO [11-07|16:14:23.856] HTTP server started endpoint=172.17.0.2:8545 auth=false prefix= cors= vhosts=localhost INFO [11-07|16:14:23.862] WebSocket enabled url=ws://127.0.0.1:8551 INFO [11-07|16:14:23.862] HTTP server started endpoint=127.0.0.1:8551 auth=true prefix= cors=localhost vhosts=localhost INFO [11-07|16:14:23.868] Transaction pool price threshold updated price=0 INFO [11-07|16:14:23.868] Updated mining threads threads=0 INFO [11-07|16:14:23.868] Transaction pool price threshold updated price=1 INFO [11-07|16:14:23.868] Etherbase automatically configured address=0xA9CB6DB62D6673ae5CD79D0d29796Dd9DF1d1A5e INFO [11-07|16:14:23.875] Commit new sealing work number=1 sealhash=6ca53b..19dc17 uncles=0 txs=0 gas=0 fees=0 elapsed=6.285ms INFO [11-07|16:14:23.877] Commit new sealing work number=1 sealhash=6ca53b..19dc17 uncles=0 txs=0 gas=0 fees=0 elapsed=8.056ms
networkid
--networkid参数需要与genesis.json配置文件中的chainId值一致。
http.api
若--http.api设置错误会出现如下错误
1
ERROR[11-07|16:13:36.346] Unavailable modules in HTTP API list unavailable=[db] available="[admin debug web3 eth txpool personal ethash miner net]"
需要按照available中规定的内容进行配置--http.api参数。
attach交互
接下来需要attach到以太坊节点,在geth节点启动过程中有这样一条日志
1
INFO [11-07|16:14:23.848] IPC endpoint opened url=/root/eth-data/geth.ipc
没错,你猜对了,就是要用这个endpoint进行attach
1 2 3 4 5 6 7 8 9 10 11
# geth attach ipc:/root/eth-data/geth.ipc Welcome to the Geth JavaScript console!
INFO [11-07|17:59:54.021] Successfully sealed new block number=1 sealhash=84eaaa..f4d2c5 hash=925c9a..d8cb75 elapsed=1h30m51.894s INFO [11-07|17:59:54.022] 🔨 mined potential block number=1 hash=925c9a..d8cb75 INFO [11-07|17:59:54.026] Commit new sealing work number=2 sealhash=865003..0e32da uncles=0 txs=0 gas=0 fees=0 elapsed=1.991ms INFO [11-07|17:59:54.027] Commit new sealing work number=2 sealhash=865003..0e32da uncles=0 txs=0 gas=0 fees=0 elapsed=3.070ms INFO [11-07|17:59:54.428] Generating DAG in progress epoch=1 percentage=0 elapsed=3.563s INFO [11-07|17:59:56.581] Successfully sealed new block number=2 sealhash=865003..0e32da hash=f1224d..9dc4b8 elapsed=2.554s INFO [11-07|17:59:56.582] 🔨 mined potential block number=2 hash=f1224d..9dc4b8 INFO [11-07|17:59:56.584] Commit new sealing work number=3 sealhash=8de6d6..c8886e uncles=0 txs=0 gas=0 fees=0 elapsed="906.417µs" INFO [11-07|17:59:56.585] Commit new sealing work number=3 sealhash=8de6d6..c8886e uncles=0 txs=0 gas=0 fees=0 elapsed=2.271ms INFO [11-07|17:59:57.730] Successfully sealed new block number=3 sealhash=8de6d6..c8886e hash=42a018..4e7ef3 elapsed=1.146s INFO [11-07|17:59:57.731] 🔨 mined potential block number=3 hash=42a018..4e7ef3 INFO [11-07|17:59:57.733] Commit new sealing work number=4 sealhash=26af07..609e57 uncles=0 txs=0 gas=0 fees=0 elapsed=1.165ms
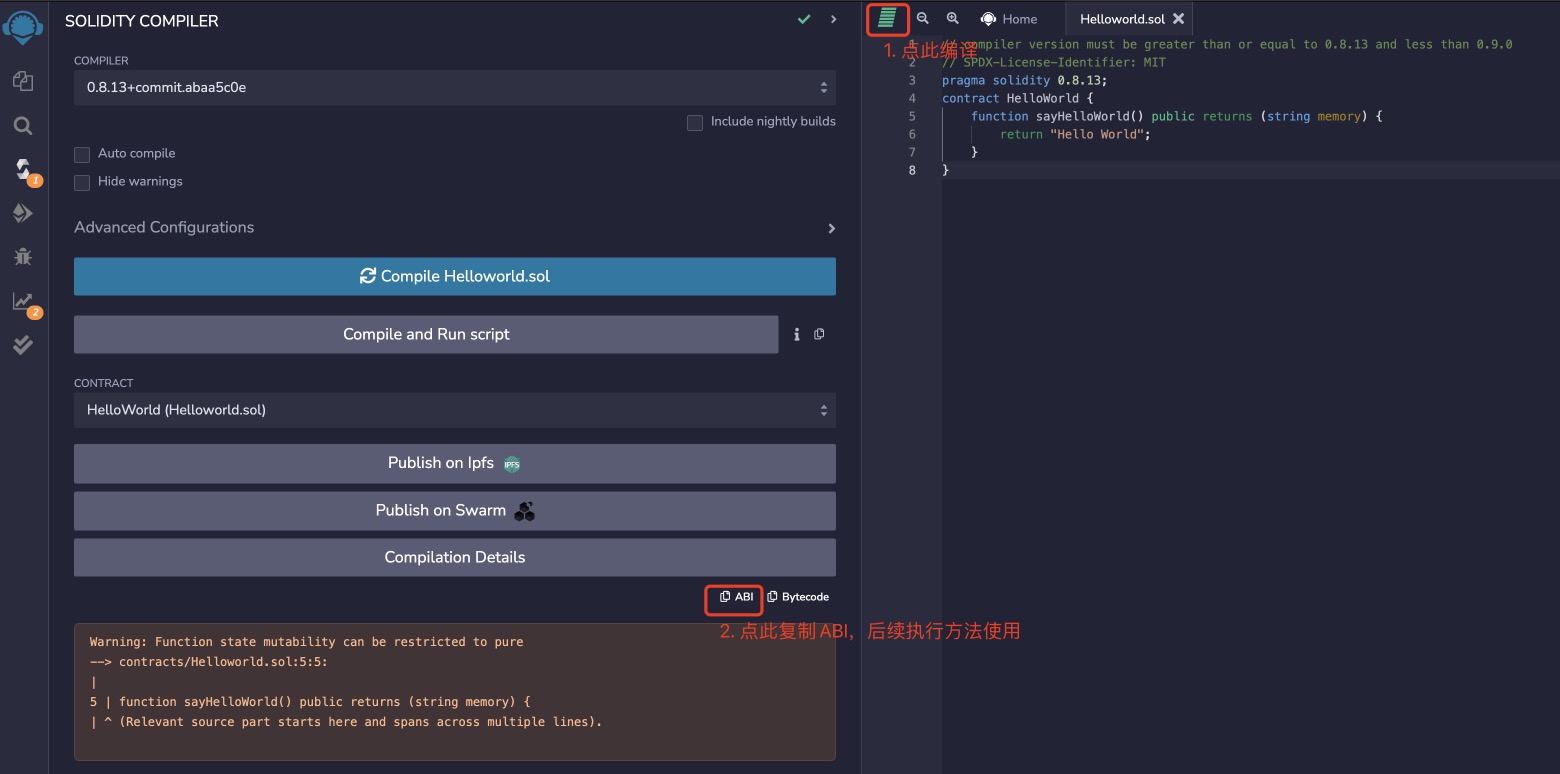
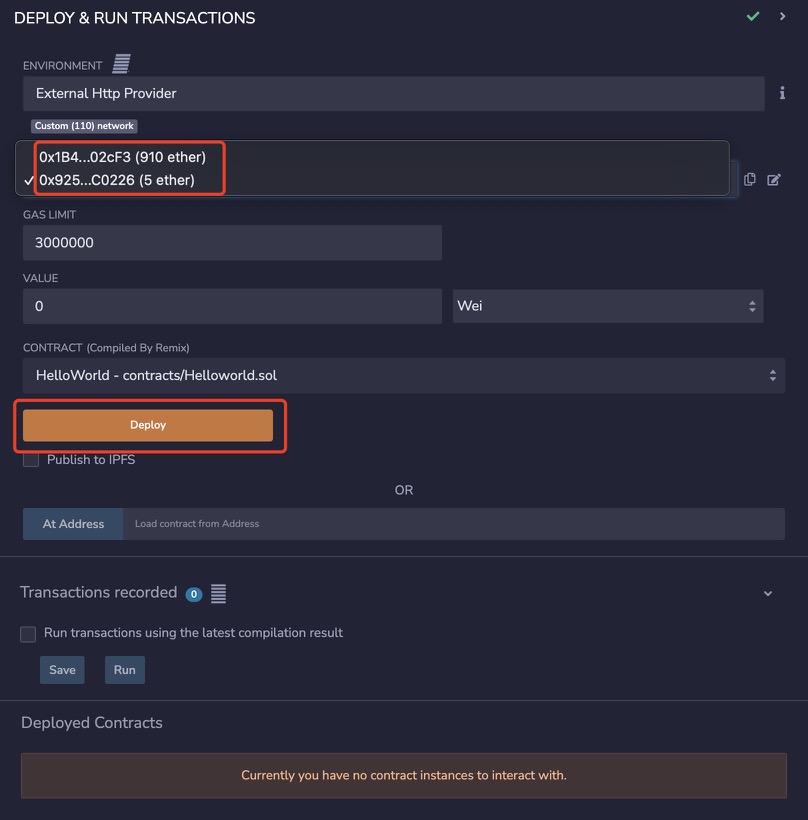
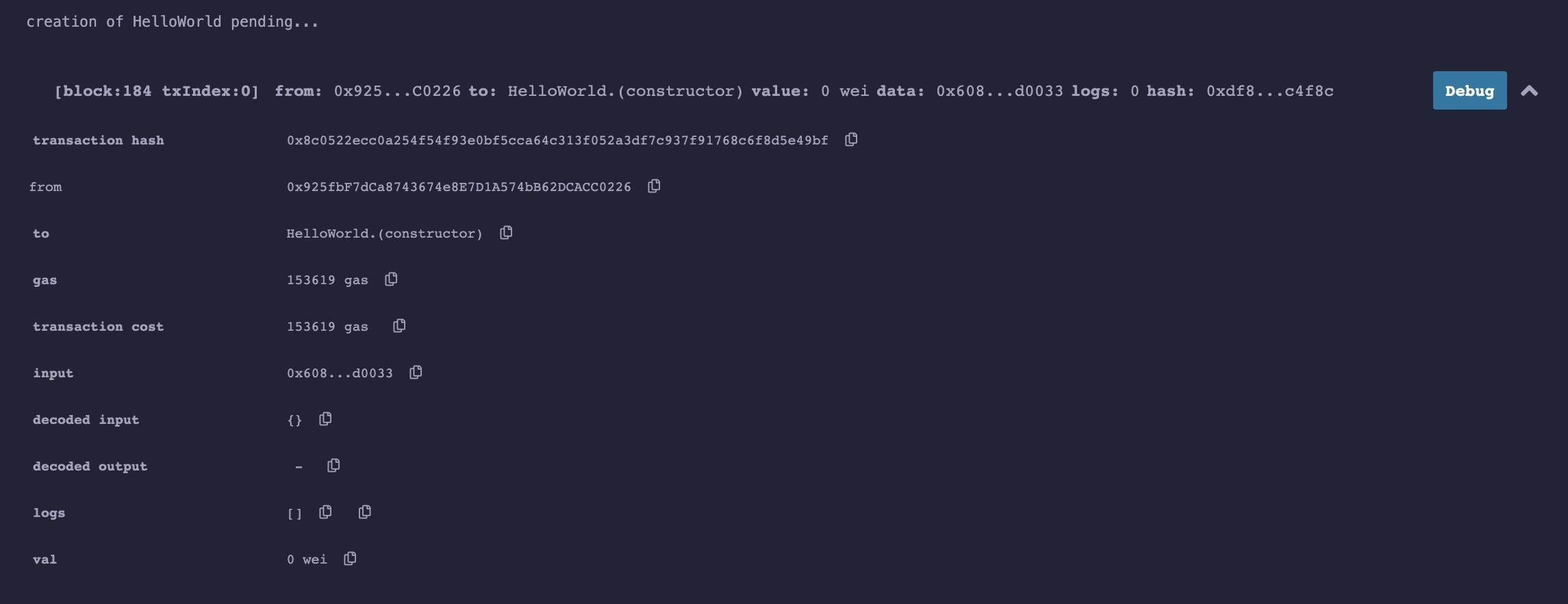
// compiler version must be greater than or equal to 0.8.13 and less than 0.9.0 // SPDX-License-Identifier: MIT pragma solidity 0.8.13; contract HelloWorld { function sayHelloWorld() public returns (string memory) { return "Hello World"; } }
/** * @brief A standard container which offers fixed time access to * individual elements in any order. * * @ingroup sequences * * @tparam _Tp Type of element. * @tparam _Alloc Allocator type, defaults to allocator<_Tp>. * * Meets the requirements of a <a href="tables.html#65">container</a>, a * <a href="tables.html#66">reversible container</a>, and a * <a href="tables.html#67">sequence</a>, including the * <a href="tables.html#68">optional sequence requirements</a> with the * %exception of @c push_front and @c pop_front. * * In some terminology a %vector can be described as a dynamic * C-style array, it offers fast and efficient access to individual * elements in any order and saves the user from worrying about * memory and size allocation. Subscripting ( @c [] ) access is * also provided as with C-style arrays. */ template<typename _Tp, typename _Alloc = std::allocator<_Tp> > class vector : protected _Vector_base<_Tp, _Alloc> { #ifdef _GLIBCXX_CONCEPT_CHECKS // Concept requirements. typedeftypename _Alloc::value_type _Alloc_value_type; # if __cplusplus < 201103L __glibcxx_class_requires(_Tp, _SGIAssignableConcept) # endif __glibcxx_class_requires2(_Tp, _Alloc_value_type, _SameTypeConcept) #endif
#if __cplusplus >= 201103L static_assert(is_same<typename remove_cv<_Tp>::type, _Tp>::value, "std::vector must have a non-const, non-volatile value_type"); # if __cplusplus > 201703L || defined __STRICT_ANSI__ static_assert(is_same<typename _Alloc::value_type, _Tp>::value, "std::vector must have the same value_type as its allocator"); # endif #endif