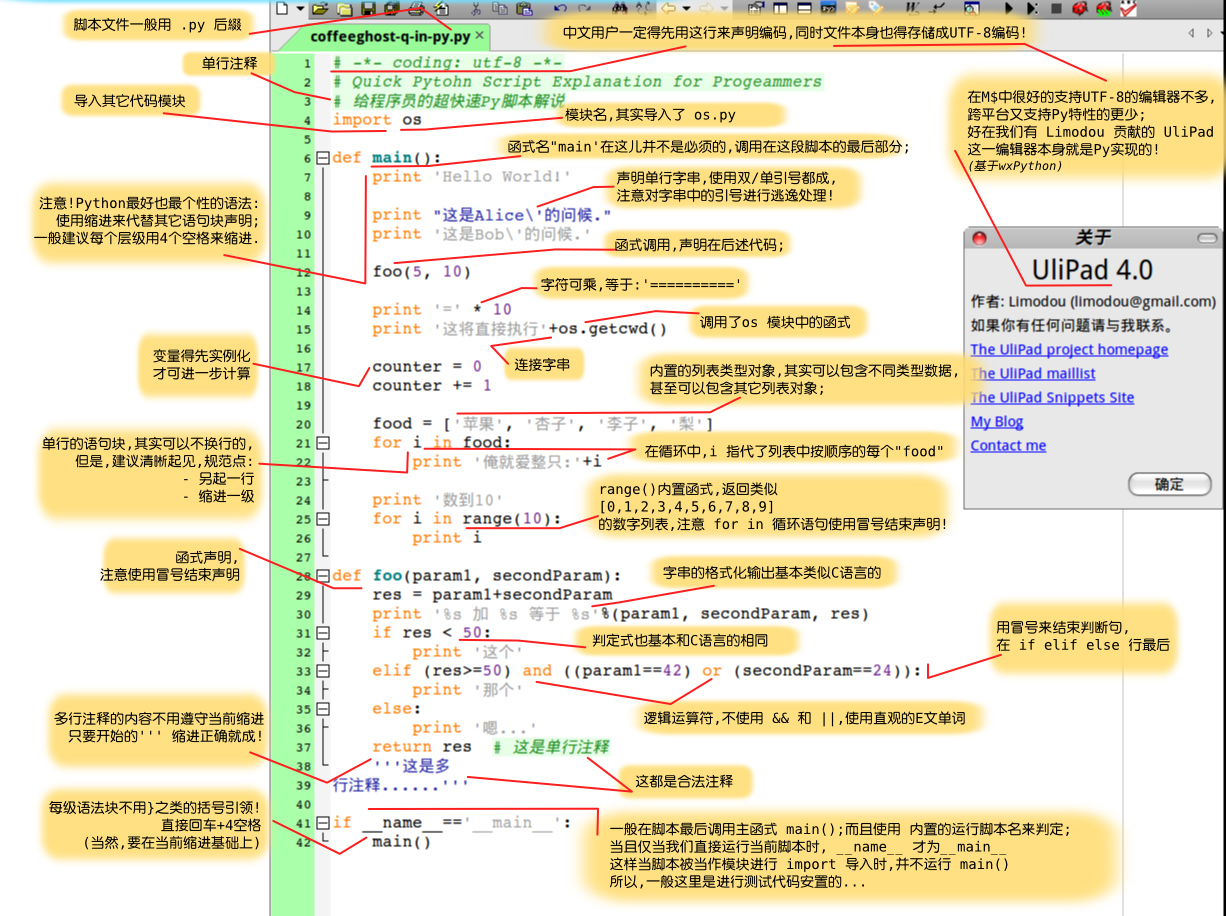
and , exec , not , assert , finally , or , break , for , pass , class , from , print , countinue , global , raise , def , if , return , del , import , try , elif , in , while , else , is , with , except , lambda , yield
>>> defcreateGenerator(): ... mylist = range(3) ... for i in mylist: ... yield i*i ... >>> mygenerator = createGenerator() # create a generator >>> print(mygenerator) # mygenerator is an object! <generator object createGenerator at 0xb7555c34> >>> for i in mygenerator: ... print(i) 0 1 4
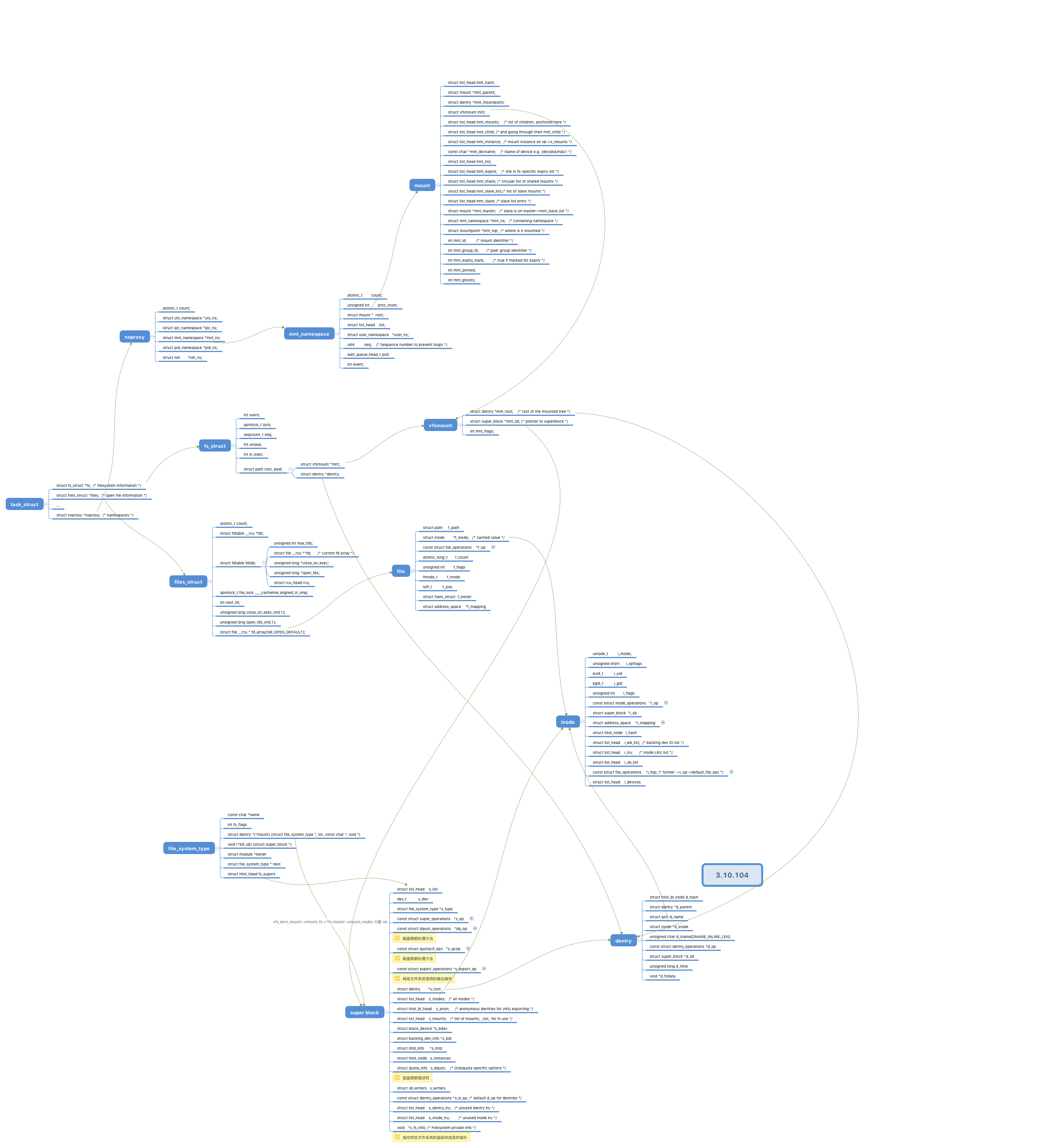
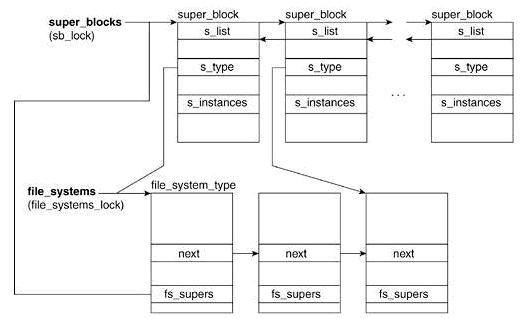
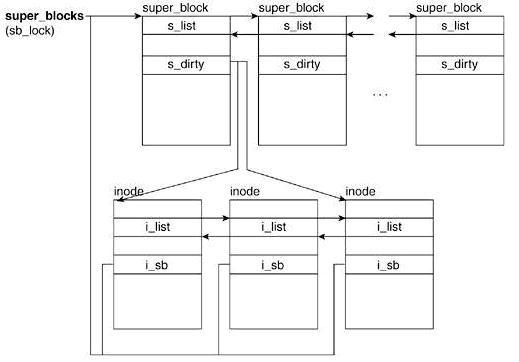
/* Granularity of c/m/atime in ns. Cannot be worse than a second */ u32 s_time_gran;
/* The next field is for VFS *only*. No filesystems have any business * even looking at it. You had been warned. */ structmutexs_vfs_rename_mutex;/* Kludge */
/* Filesystem subtype. If non-empty the filesystem type field * in /proc/mounts will be "type.subtype" */ char *s_subtype;
/* Saved mount options for lazy filesystems using * generic_show_options() */ char __rcu *s_options; conststructdentry_operations *s_d_op;/* default d_op for dentries */
/* Saved pool identifier for cleancache (-1 means none) */ int cleancache_poolid; structshrinkers_shrink;/* per-sb shrinker handle */
/* Number of inodes with nlink == 0 but still referenced */ atomic_long_t s_remove_count;
/* Being remounted read-only */ int s_readonly_remount; };
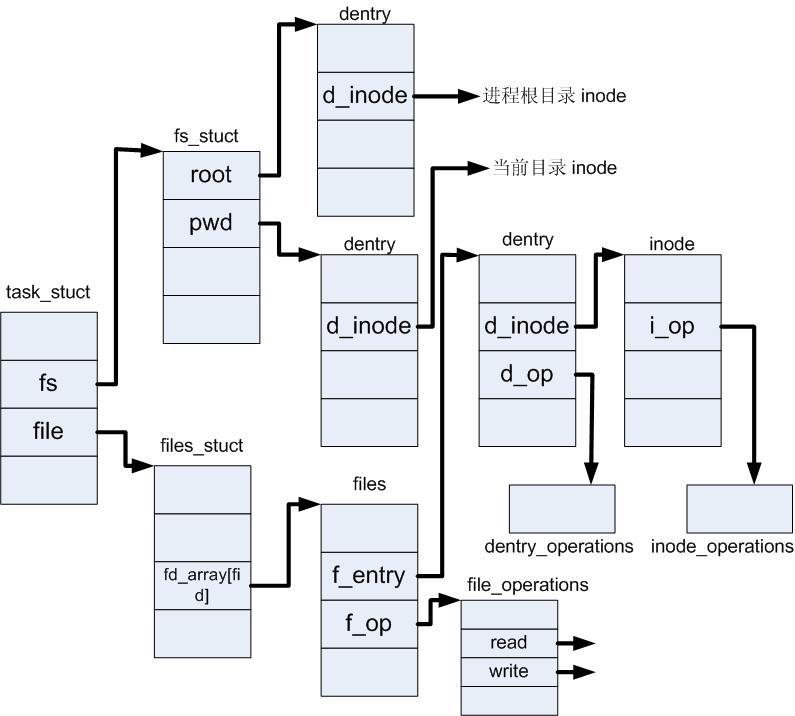
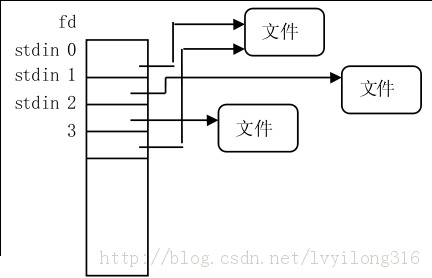
/* * Protects f_ep_links, f_flags, f_pos vs i_size in lseek SEEK_CUR. * Must not be taken from IRQ context. */ spinlock_t f_lock; atomic_long_t f_count; /* 记录使用文件对象的进程数 */ unsignedint f_flags; fmode_t f_mode; loff_t f_pos; structfown_structf_owner; conststructcred *f_cred; structfile_ra_statef_ra;
u64 f_version; #ifdef CONFIG_SECURITY void *f_security; #endif /* needed for tty driver, and maybe others */ void *private_data;
#ifdef CONFIG_EPOLL /* Used by fs/eventpoll.c to link all the hooks to this file */ structlist_headf_ep_links; structlist_headf_tfile_llink; #endif/* #ifdef CONFIG_EPOLL */ structaddress_space *f_mapping; #ifdef CONFIG_DEBUG_WRITECOUNT unsignedlong f_mnt_write_state; #endif };
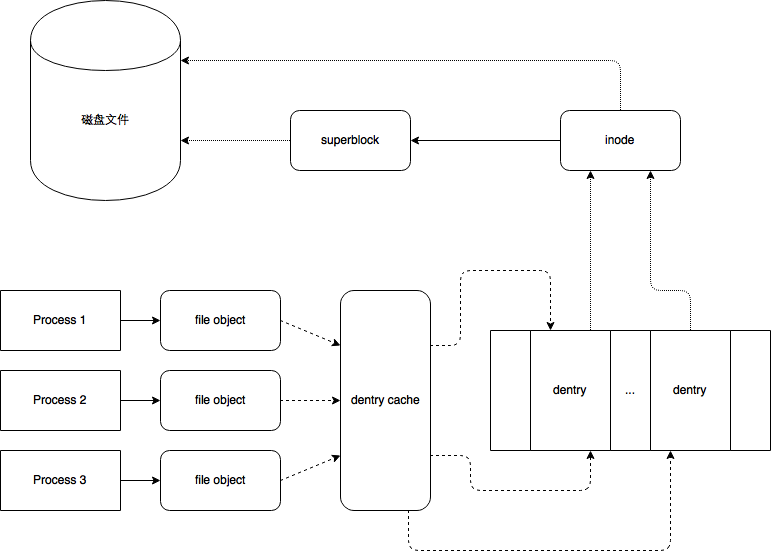
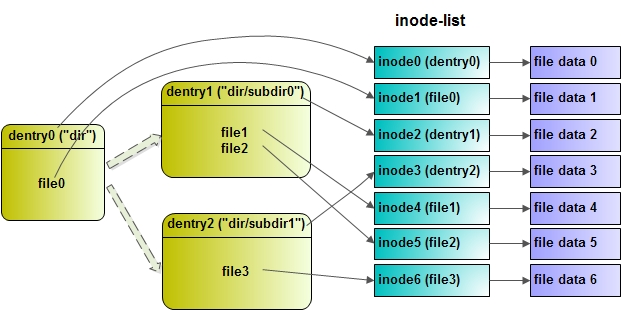
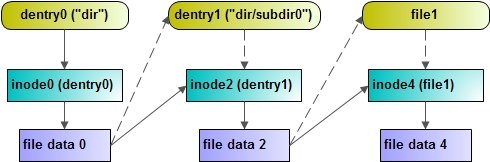
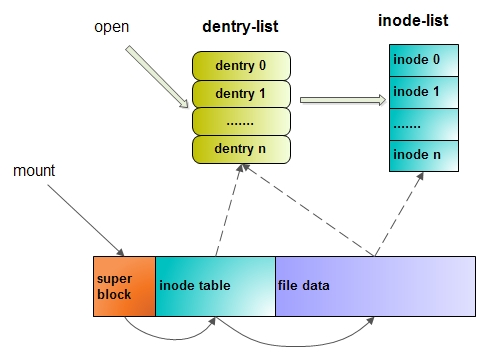
structdentry { /* RCU lookup touched fields */ unsignedint d_flags; /* protected by d_lock */ seqcount_t d_seq; /* per dentry seqlock */ structhlist_bl_noded_hash;/* lookup hash list */ structdentry *d_parent;/* parent directory */ structqstrd_name; structinode *d_inode;/* Where the name belongs to - NULL is * negative */ unsignedchar d_iname[DNAME_INLINE_LEN]; /* small names */ /* Ref lookup also touches following */ unsignedint d_count; /* protected by d_lock */ spinlock_t d_lock; /* per dentry lock */ conststructdentry_operations *d_op; structsuper_block *d_sb;/* The root of the dentry tree */ unsignedlong d_time; /* used by d_revalidate */ void *d_fsdata; /* fs-specific data */
structlist_headd_lru;/* LRU list */ structlist_headd_child;/* child of parent list */ /* 如果当前目录项是一个目录,那么该目录项通过这个字段加入到父目录的d_subdirs链表当中。这个字段中的next和prev指针分别指向父目录中的另外两个子目录 */ structlist_headd_subdirs;/* our children */ /* 如果当前目录项是一个目录,那么该目录下所有的子目录(一级子目录)形成一个链表。该字段是这个链表的表头 */ /* * d_alias and d_rcu can share memory */ union { structhlist_noded_alias;/* inode alias list */ /* 索引节点中的i_dentry指向了它目录项,目录项中的d_alias,d_inode又指会了索引节点对象 一个inode可能对应多个目录项,所有的目录项形成一个链表。inode结构中的i_dentry即为这个链表的头结点。当前目录项以这个字段处于i_dentry链表中。该字段中的prev和next指针分别指向与该目录项同inode的其他两个(如果有的话)目录项 */ structrcu_headd_rcu; } d_u; };
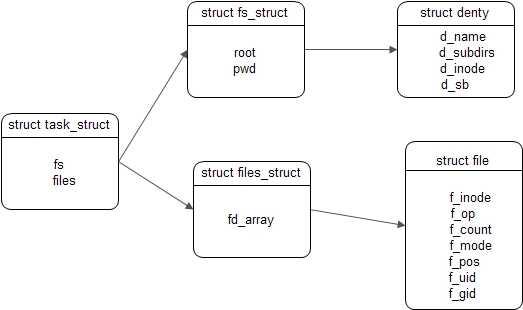
structfiles_struct { /* * read mostly part */ atomic_t count; structfdtable __rcu *fdt; structfdtablefdtab; /* * written part on a separate cache line in SMP */ spinlock_t file_lock ____cacheline_aligned_in_smp; int next_fd; unsignedlong close_on_exec_init[1]; unsignedlong open_fds_init[1]; structfile __rcu * fd_array[NR_OPEN_DEFAULT]; };
type 主要包括host,net,port,例如 host 210.27.48.2, 指明 210.27.48.2是一台主机,net 202.0.0.0指明202.0.0.0是一个网络地址,port 23 指明端口号是23。如果没有指定类型,缺省的类型是host。
dir 主要包括src,dst,dst or src,dst and src, 这些关键字指明了传输的方向。举例说明,src 210.27.48.2 ,指明ip包中源地址是 210.27.48.2 , dst net 202.0.0.0 指明目的网络地址是202.0.0.0。如果没有指明 方向关键字,则缺省是src or dst关键字。
proto 主要包括fddi,ip,arp,rarp,tcp,udp等类型。Fddi指明是在FDDI (分布式光纤数据接口网络)上的特定的网络协议,实际上它是”ether”的别名,fddi和ether 具有类似的源地址和目的地址,所以可以将fddi协议包当作ether的包进行处理和分析。 其他的几个关键字就是指明了监听的包的协议内容。如果没有指定任何协议,则tcpdump 将会 监听所有协议的信息包。
put 'student', 'row1', 'id:val', '1' put 'student', 'row1', 'name:val', 'Tony' put 'student', 'row2', 'id:val', '2' put 'student', 'row2', 'name:val', 'Mike'
注意:在插入数据的时候一定要指定column (如id:val, name:val) 直接使用column family (如 id, name) 去存数据会导致后面Hive 建表的时候有问题。
CREATE EXTERNAL TABLE student(key string, id int, name string) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ("hbase.columns.mapping" = "id:val,name:val") TBLPROPERTIES("hbase.table.name" = "student");
Hive中建立一个新的空表
1 2 3 4
hive> select * from student; OK row1 1 Tony row2 2 Mike
FreeBSD 下的虚拟技术 bhyve (The BSD Hypervisor) 是去年1月份正式发布的,包含在了 FreeBSD 10.0 发行版中。今天要玩的这个 xhyve 是基于 bhyve 的 Mac OS X 移植版本,也就是说我们想在 Mac 上运行 Linux 的话除了 VirtualBox, VMware Fusion 外,现在有了第三种选择。
xhyve is a lightweight virtualization solution for OS X that is capable of running Linux. It is a port of FreeBSD’s bhyve, a KVM+QEMU alternative written by Peter Grehan and Neel Natu.
特点:
super lightweight, only 230 KB in size
completely standalone, no dependencies
the only BSD-licensed virtualizer on OS X
does not require a kernel extension (bhyve’s kernel code was ported to user mode code calling into Hypervisor.framework)
multi-CPU support
networking support
can run off-the-shelf Linux distributions (and could be extended to run other operating systems)
xhyve may make a good solution for running Docker on your Mac, for instance.
install
search xhyver:
1 2 3 4 5 6 7 8 9
$ brew info xhyve xhyve: stable 0.2.0 (bottled), HEAD xhyve, lightweight macOS virtualization solution based on FreeBSD's bhyve https://github.com/mist64/xhyve /usr/local/Cellar/xhyve/HEAD-1f1dbe3 (11 files, 11.2MB) * Built from source on 2017-08-24 at 12:12:21 From: https://github.com/Homebrew/homebrew-core/blob/master/Formula/xhyve.rb ==> Requirements Required: macOS >= 10.10 ✔
RUN yum update -y RUN yum install -y java-1.8.0-openjdk.x86_64 RUNecho"JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.141-1.b16.el7_3.x86_64/jre" | tee -a /etc/bashrc RUNecho"export JAVA_HOME" | tee -a /etc/bashrc
Could not establish connection to jdbc:hive2://192.168.0.51:10000: Required field 'serverProtocolVersion' is unset! Struct:TOpenSessionResp(status:TStatus(statusCode:ERROR_STATUS, infoMessages:[*org.apache.hive.service.cli.HiveSQLException:Failed to open new session: java.lang.RuntimeException: java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: hive is not allowed to impersonate hive:13:12, org.apache.hive.service.cli.session.SessionManager:openSession:SessionManager.java:266, org.apache.hive.service.cli.CLIService:openSessionWithImpersonation:CLIService.java:202, org.apache.hive.service.cli.thrift.ThriftCLIService:getSessionHandle:ThriftCLIService.java:402, org.apache.hive.service.cli.thrift.ThriftCLIService:OpenSession:ThriftCLIService.java:297, org.apache.hive.service.cli.thrift.TCLIService$Processor$OpenSession:getResult:TCLIService.java:1253, org.apache.hive.service.cli.thrift.TCLIService$Processor$OpenSession:getResult:TCLIService.java:1238, org.apache.thrift.ProcessFunction:process:ProcessFunction.java:39, org.apache.thrift.TBaseProcessor:process:TBaseProcessor.java:39, org.apache.hive.service.auth.TSetIpAddressProcessor:process:TSetIpAddressProcessor.java:56, org.apache.thrift.server.TThreadPoolServer$WorkerProcess:run:TThreadPoolServer.java:285, java.util.concurrent.ThreadPoolExecutor:runWorker:ThreadPoolExecutor.java:1145, java.util.concurrent.ThreadPoolExecutor$Worker:run:ThreadPoolExecutor.java:615, java.lang.Thread:run:Thread.java:745, *java.lang.RuntimeException:java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: hive is not allowed to impersonate hive:21:8, org.apache.hive.service.cli.session.HiveSessionProxy:invoke:HiveSessionProxy.java:83, org.apache.hive.service.cli.session.HiveSessionProxy:access$000:HiveSessionProxy.java:36, org.apache.hive.service.cli.session.HiveSessionProxy$1:run:HiveSessionProxy.java:63, java.security.AccessController:doPrivileged:AccessController.java:-2, javax.security.auth.Subject:doAs:Subject.java:415, org.apache.hadoop.security.UserGroupInformation:doAs:UserGroupInformation.java:1657, org.apache.hive.service.cli.session.HiveSessionProxy:invoke:HiveSessionProxy.java:59, com.sun.proxy.$Proxy19:open::-1, org.apache.hive.service.cli.session.SessionManager:openSession:SessionManager.java:258, *java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: hive is not allowed to impersonate hive:26:5, org.apache.hadoop.hive.ql.session.SessionState:start:SessionState.java:494, org.apache.hive.service.cli.session.HiveSessionImpl:open:HiveSessionImpl.java:137, sun.reflect.GeneratedMethodAccessor11:invoke::-1, sun.reflect.DelegatingMethodAccessorImpl:invoke:DelegatingMethodAccessorImpl.java:43, java.lang.reflect.Method:invoke:Method.java:606, org.apache.hive.service.cli.session.HiveSessionProxy:invoke:HiveSessionProxy.java:78, *org.apache.hadoop.ipc.RemoteException:User: hive is not allowed to impersonate hive:45:19, org.apache.hadoop.ipc.Client:call:Client.java:1427, org.apache.hadoop.ipc.Client:call:Client.java:1358, org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker:invoke:ProtobufRpcEngine.java:229, com.sun.proxy.$Proxy14:getFileInfo::-1, org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB:getFileInfo:ClientNamenodeProtocolTranslatorPB.java:771, sun.reflect.GeneratedMethodAccessor7:invoke::-1, sun.reflect.DelegatingMethodAccessorImpl:invoke:DelegatingMethodAccessorImpl.java:43, java.lang.reflect.Method:invoke:Method.java:606, org.apache.hadoop.io.retry.RetryInvocationHandler:invokeMethod:RetryInvocationHandler.java:252, org.apache.hadoop.io.retry.RetryInvocationHandler:invoke:RetryInvocationHandler.java:104, com.sun.proxy.$Proxy15:getFileInfo::-1, org.apache.hadoop.hdfs.DFSClient:getFileInfo:DFSClient.java:2116, org.apache.hadoop.hdfs.DistributedFileSystem$22:doCall:DistributedFileSystem.java:1315, org.apache.hadoop.hdfs.DistributedFileSystem$22:doCall:DistributedFileSystem.java:1311, org.apache.hadoop.fs.FileSystemLinkResolver:resolve:FileSystemLinkResolver.java:81, org.apache.hadoop.hdfs.DistributedFileSystem:getFileStatus:DistributedFileSystem.java:1311, org.apache.hadoop.fs.FileSystem:exists:FileSystem.java:1424, org.apache.hadoop.hive.ql.session.SessionState:createRootHDFSDir:SessionState.java:568, org.apache.hadoop.hive.ql.session.SessionState:createSessionDirs:SessionState.java:526, org.apache.hadoop.hive.ql.session.SessionState:start:SessionState.java:480], errorCode:0, errorMessage:Failed to open new session: java.lang.RuntimeException: java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: hive is not allowed to impersonate hive), serverProtocolVersion:null)
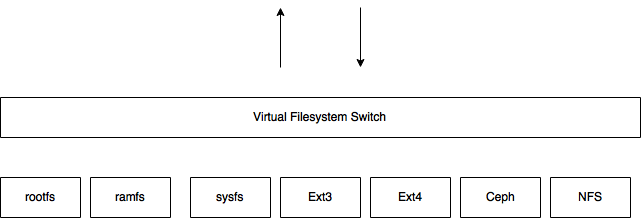
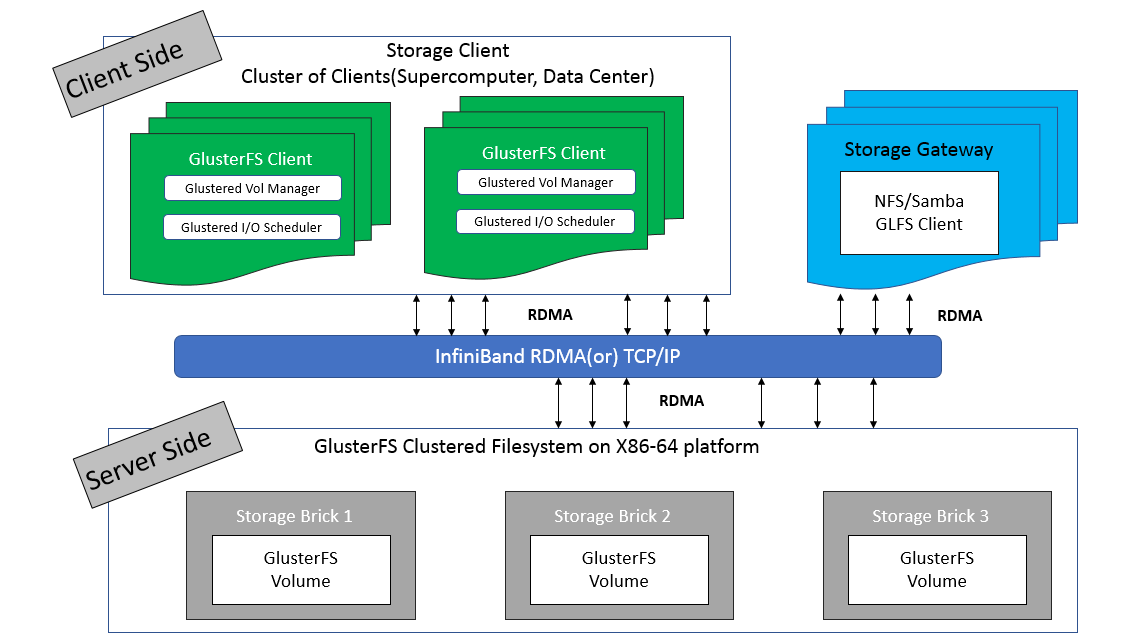
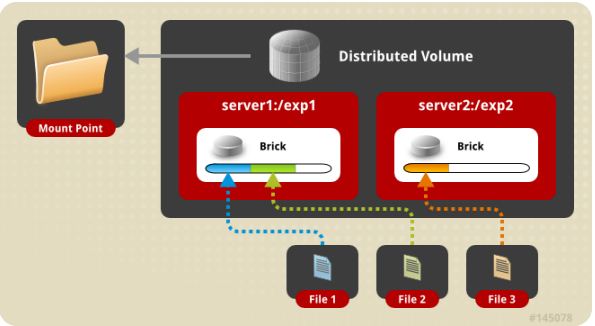
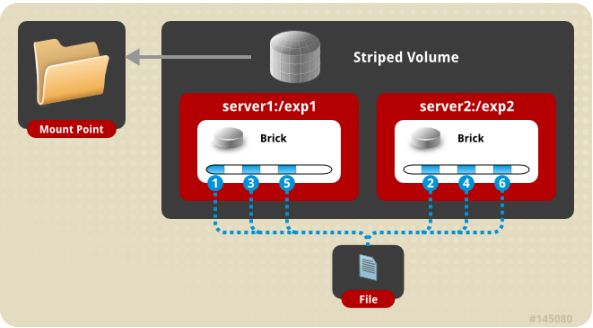
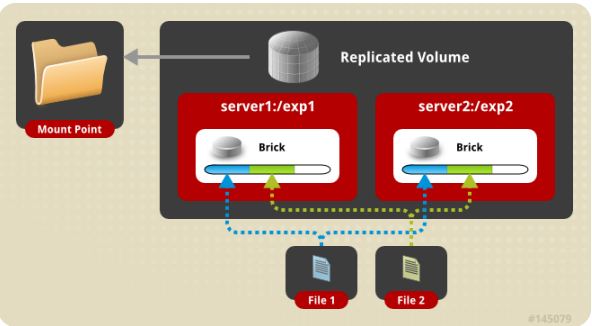
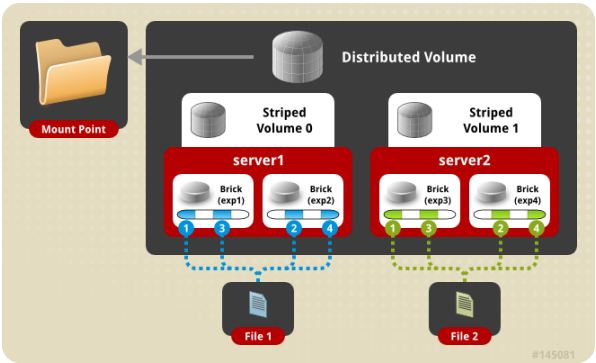
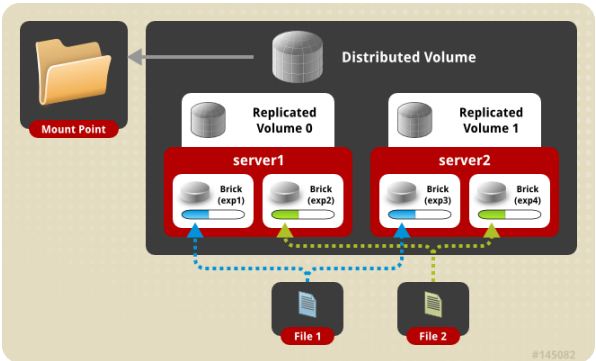
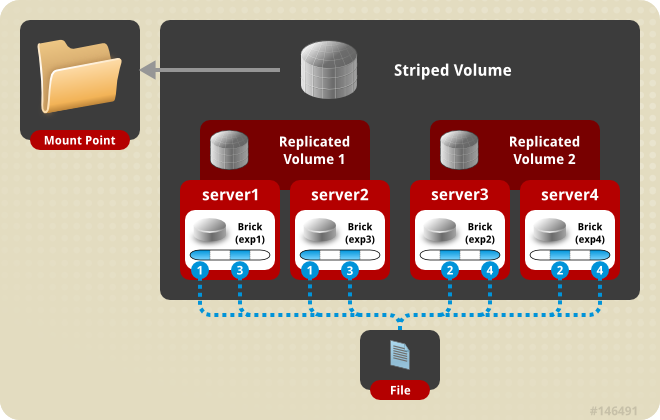
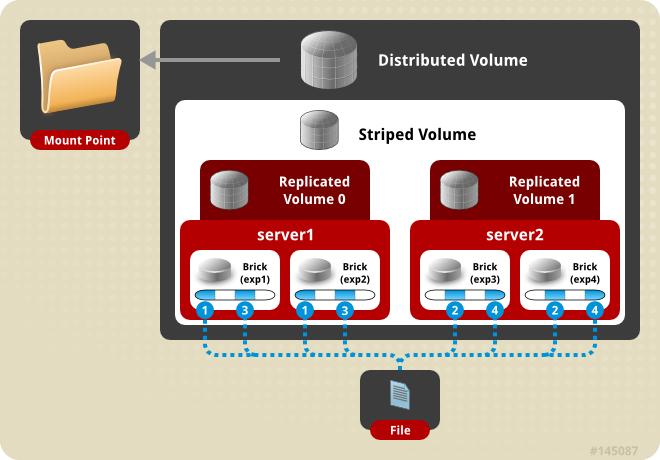
存储服务器主要提供基本的数据存储功能,客户端弥补了没有元数据服务器的问题,承担了更多的功能,包括数据卷管理、I/O 调度、文件定位、数据缓存等功能,利用 FUSE(File system in User Space)模块将 GlusterFS 挂载到本地文件系统之上,实现 POSIX 兼容的方式来访问系统数据。